
Do I really need to go through this again? Argh!
As long-time readers will remember, a while back, I had an encounter with
a crackpot named Jules Gilbert who claimed to be able to cyclically compress
files. That is, he could take a particular input file, compress it, do
something to it, and then compress it again, making it smaller. He claimed to
be able to do this for any input.
And to make it more annoying, his claim to be able to do this brilliant
magical cyclical compression was attached to an obnoxious christian “I want to
save you soul” rant, where he effectively offered to share the profits from
this brilliant invention with me, if I’d only give him the chance to tell me
about Jesus.
I tried to get rid of the schmuck. I asked him to leave me alone politely.
Then I asked him to leave me alone not-so politely. Then I asked him to
leave me alone very, very rudely. Then I publicly mocked him on this blog.
After the last, he finally seemed to take the hint and go away.
Unfortunately, good things often don’t last. And yesterday, I received
another new message from him, bragging about the results of his uber-magical
compression system. He has now perfected it to the point where he can take
any input file, and compress it down to about 50K:
I am now compressing single bit as:
I use C code to pack up one bit to a byte and call bzip2’s compress
buffer.I print the result and compute the size.
(I did this for both gzip and bzip2.) Gzip didn’t compress; it gave
me back about 6.25, but I needed at least 8.0.And bzip2 gave it to me. About 8.2 and higher. (This is with no
actual I/O, just buffer to buffer.)This was with random data. At least that’s what people call it.
Bzip2 data. (It looks pretty random to me.)I expect to show up at a friend’s house and show him the system on
Monday. THIS IS NOT A COMPLETE SYSTEM, but it’s not just research
either. The input was randomly chosen (not by me, by a C function,)
and the program has been arranged to simply open another file when a
current file is exhausted.Every input file has been compressed once with bzip2. Each input file
is at least 5k bytes and was chosen with the intent to represent all
popular OS’s somewhat equally.This program is easily able to process MN’s 415k file. And since it
uses 256 byte blocks, I can bring it down to about 50k (number
demonstrated in testing.) Another way to say this is that (with this
program,) all files greater than about 50k can be made that small.This is the simplist system I have ever made that uses my “modern”
techniques (I mean, not my LSQ ideas of a decade ago.) i started
coding it this morning, to see if a certain idea worked…I’m trying to drop bzip but it’s pretty good! I’m also trying to
modulate my input to it, in order to obtain a gain from the pattern
recognition (the BWT may not be an actual FFT but it’s a similar
idea.) If I can do this I will keep it.If all this is greek to you, here’s the thing: Just about every other
computer scientist in the whole wide world believes this is
impossible. Why is this valuable? Because it means that all files
and messages can be compressed in while in transit to, say, 50k —
probably much less. (Or while sitting on a CD-ROM or DVD.)
I love that line in there: “Just about every other computer scientist in
the whole wide world believes this is impossible”.
Jules, baby, belief has nothing to do with it.
Let’s walk through this one more time. What is a compression system?
Fundamentally, it’s a function with three properties:
- It’s computably invertible. That is, if
is an input, and
is the compressed output, there must be a computable function
.
- It’s one-to-one. It must be one-to-one – because if it weren’t it wouldn’t be invertible. If there were two values,
where
, then
wouldn’t be able to decompress – because it wouldn’t know which value to return for
.
- For some set of interesting
In an ideal compression function, you’d have the property that f is total, and  len(f(x)) < len(x)")
Ideal compression functions are impossible. And it’s very easy to prove. Suppose you had a compression function which could remove one bit – just one bit – from any input file. Consider the set of file with N bits. You’d like to be able to compress those to N-1 bits. You can’t do it. Why? Because there are 


You might respond: but I’ve got gzip and bzip2 on my computer, and they clearly work! Well, that’s true. They work. For some inputs. But not for all. gzip and bzip are based on compression algorithms that exploit the structure of their typical inputs. Text files typically have a huge amount of repetition in them – and the LZW family of algorithms that common compressors are built on do a very good job of exploiting that. But they don’t work on everything. Just for one example, I tried compressing an MP3 on my disk. Before compression, its length was 7937898 bytes, After compression by bzip, it’s length was 7972829. “Compressing” the file actually added nearly 35,000 bytes. Our compression functions work pretty well on the types of data for which they’re designed, which contain lots of redundancy. But a true, general, ideal compression system? It’s impossible.
The usual crackpot response to this is something along the lines of “You just believe it’s impossible. Scientists have been wrong before.”
The thing is, there are proofs, and then there are proofs. Every proof is dependent on its basic premises. If those premises turn out to be false, then the proof is also false. This has happened lot of times before. For example, back when I was in high school, there was an absolute proof, built using Shannon’s information theory, that you couldn’t transmit data with more than 600 modulations per second over a telephone line. That meant that a modem couldn’t transmit data any faster than 600 bits per second. Not just the kind of modem they built back then, but any modem – because it was a fundamental property of the bandwidth of the telephone line.
It turned out to be wrong. The proof itself didn’t have any problems – but the model it used for the bandwidth capacity of a telephone line was incorrect. So by the time I started college, 1200bps modems were common; by the time I got to grad school, 28,800bps modems were common; before broadband started hitting the scene, 56,600bps modems were common. That original proof of the bandwidth capacity of a phone line was off by a factor of 100.
But computing the bandwidth capacity of a telephone line is remarkably tricky. There are a ton of places where incorrect assumptions about the line can enter the proof – and so, while the proof itself is fine, it’s not a proof about real telephone lines.
That’s the kind of problem that you encounter in mathematical proofs about the real world. If the proof is actually valid, its validity in inescapable. But truth and validity are two different things. Truth is, in a vague sense, whether or not the validity of the proof implies anything about some real-world phenomenon that the proof is applied to. Validity is just internal consistency of the proof in its logical system. So a proof can be valid, without a particular application of that proof being true. To determine whether or not a proof is true, you need to check whether or not its axioms actually map correctly onto a real-world application.
In the case of this kind of compression nonsense, the mapping between the proof and the real world is incredibly direct. The compressor, in order to work, must be a one-to-one function. There is no way that it can decompress if it isn’t.
Mr. Gilbert claims that he can take any input file, and compress it down to 50K. That is, quite simply impossible.
There are 2400,000 possible 50K long files. That seems like an astonishingly large number. It’s larger than the number of atoms in the observable universe. It’s a number that’s really beyond the ability of our imagination to comprehend. But… I’ve got a rather large collection of music on my hard-drive. A bit over 30GB worth. The average file there is around 5 megabytes. That’s around 5,000,000 bytes, or 40,000,000 bits. There are 240,000,000 possible files that long. And Jules is claiming that he can take any of those files, and compress them to 50K. It’s an unavoidable fact that even if we restrict all files to be exactly 5,000,000 bytes long, then his system must be mapping an average of 
The number don’t lie. The proof has no holes. There’s no way to do what he claims to be doing. And I’ve explained this before – both in email to him, and in posts on this blog. But some people are so convinced of their own perfect brilliance that they think reality doesn’t apply to them. Sorry Jules, but even with the help of Jesus himself, your stuff can’t work.
“There are 2^{400,000} possible 50K long files… I’ve got a rather large collection of music on my hard-drive. A bit over 30GB worth. The average file there is around 5 megabytes… There are 2^{40,000,000} possible files that long…It’s an unavoidable fact that even if we restrict all files to be exactly 5,000,000 bytes long, then his system must be mapping an average of 2^{100} files onto each possible 50K output file. ”
Actually, I believe its much worse than that, 2^{40,000,000}/2^{400,000} = 2^{39,600,000}, so it would map an average of approximately 2^{39,600,000} input files to each individual output file.
If I remember correctly, something like this was actually published in a major magazine in the April (fool’s) issue.
A friend of mine saw it first, believed it, and phoned me. That proof of yours is so obvious it occurred to me right away on that phone call years ago.
It occurred to me reading this that maybe he just doesn’t understand the first thing about how compression works — that he doesn’t understand that he is taking a fixed set of bits and producing a fixed set of bits. Let me ‘splain:
When I was a young ‘un, maybe 9 or 10 or so, somebody mentioned the concept of file compression. (This would have been circa 1988, so not many people had ever come in contact with a compressed file, not even a GIF) Being rather computer savvy for my age, I asked, “How does that work?” The reply was that it worked by removing extra space between the bits….
Anyway, my point is, if you had some semi-mystical concept of how compression worked (like reducing the space between the bits), then the proof cited by Mark might not make any sense to you.
As far as where Jules obtained his data… I noticed he never actually mentions expanding and verifying the file! Maybe he is doing some kind of lossy transform along the way and just doesn’t even realize it…
I suspect it’s true that Jules Gilbert often skips over the step of double-checking the decompression output. But his problems go much deeper than simple misunderstanding. His ability to not acknowledge the mathematical impossibility of his scheme is a fortress of iron.
Well, if he thinks BWT and FFT are “similar ideas” then he doesn’t have even the slightest concept of how the cogs fit together inside actual compression algorithms. And without that understanding, a not-very-bright person might also have difficulty understanding the mathematical impossibility argument.
Regarding his “recursive compression” ideas, I seem to remember back in my BBS days there was a short-lived format — UC2 perhaps? — that took advantage of the fact that the lossless compression algorithms of the day were pretty far from ideal, and actually did two lossless passes on the data. At that time, it could typically get another 5-10% above and beyond the de facto standard.
Then of course people just improved the underlying algorithms and that silly idea went away…
Woah, holy crap, did he just say that BWT and FFT are “similar idea[s]”?!?!?
I am assuming by the latter he means the Burrows-Wheeler transform (a clever lossless reordering of data that improves lossless compression of data that contains a lot of strings of repeating characters) and Fast Fourier Transform (a class of algorithms for computing a Fourier transform, which has applicability in lossy image and sound compression systems).
Um, no, they are not similar ideas. At all.
That would be like saying that a crossword puzzle is a similar idea to a Jackson Pollack painting. No they are not.
No, you’re wrong. They are extremely similar ideas.
A Fourier transform by itself is a lossless transformation, but it also has (theoretical) applicability in lossless compression. In image/sound applications, the Fourier coefficients are typically quantised, which is where the loss arises. However, there’s no reason why you need do this. You could quite easily base a lossless compression algorithm for images or sound on the Fourier transform, though of course the compression rate would be worse.
At a theoretical level, the purpose of BWT for text-like data and the FT for sampled data is the same in both cases: it’s used to transform high-order redundancy into zero-order redundancy.
I’m not convinced a lossless compression algorithm based on a Fourier transform (or variant) is all that feasible. I’m pretty sure there’s typically just as much entropy in the frequency domain data as in the spatial domain data. Like you say, it’s the quantization that gives you the compression, because you drop the high-frequency data. “High-frequency” is the key — the purpose of doing the transformation in to the frequency domain is that the human eye/ear is less sensitive to high-frequency data, so you preserve the low-frequency information, and discard (or preserve with less detail) the high-frequency information. There’s no analogous selective discarding you can do in the spatial domain — it’s not like we’re more sensitive to pixels in the upper-left of an image than in the lower-right!
That said, I do see your point as to how BWT and Fourier-as-applied-to-compression are somewhat analogous, in that they transform high-order compressibility into low-order compressibility (I disagree that both are transforming redundancy, because lossy compression algorithms exploiting Fourier and variants do not typically exploit redundancy per se).
So from a compression standpoint, I would agree they are analogous, but I would still assert they are not really “similar ideas” from any standpoint. And certainly Crazy Jules’ comment about “BWT may not be an actual FFT” is bizarre.
I haven’t looked at the details, but a Google search reveals a number of relevant hits for “lossless subband coding”.
BTW, I agree 100% with your last sentence.
Only reservation – with the help of Jesus himself, the stuff WOULD work, because Jesus – if he existed would have out-of-band storage available in heaven, and could thus compress the file down to a single byte.
Even though that gives you only 256 possible files, each actual INSTANCE of a file would be able to access memory in heaven to reconstitute itself.
No, sorry, JesusZip only works on fish and bread.
@ Real Analysis:
In a generalized form, simply knowing that Q is dependent on P is powerful even if we do not fully understand the nature of that dependence.
Would that be cloud storage?
Several years ago I used to read comp.compression and Jules Gilbert was a perennial there. Every year or so he’d reappear banging on the latest version of his recursive compression algorithm. And most every time there’d be someone who hadn’t yet gotten sick of him, and they’d get roped into yet another thread of trying to make Jules Gilbert see reason. Never worked.
Wait, no, wait, holy crap, I think I just parsed this, and he is crazy!
If I understand him correctly…
He took a stream of data, and expanded each byte into eight bytes, each of which was either zero or had a single bit set. So for instance, he would expand the string 0x85 c7 into: 0x80 0x00 0x00 0x00 0x00 0x04 0x00 0x01 0x80 0x40 0x00 0x00 0x00 0x04 0x02 0x01. Yes, I really think that is what he is doing. Let’s call this the Really Stupid Transform, or RST for short.
Then he compressed it. And he needed to get >= 8:1 compression, so that he’d at least be back to where he started.
This would be consistent with his data. GZIP, with default settings, would perform poorly because — by default — it uses a static Huffman tree, so even though the LZW string matching would perform marvelously, there would be some wasted bits in the actual Huffman encoded data. BZIP2 OTOH is going to have repeated strings up the wazoo and ought to do wonderfully. For random pre-RST data, an ideal compression system would get a little less than 8:1 compression of RST data. (which means slightly worse than 1:1 in relation to the pre-RST data). But it appears he only did one trial, and 8.2:1 is by no means an unrealistic result, if his source data wasn’t completely random.
As a little experiment, I created a little RST “compression” program, gave it 1MB from /dev/random, then bzip2’d it and gzip’d it. I didn’t get quite as “good” results as our friend Jules, but it does demonstrate what I was talking about: bzip2 got 6.5:1 on the RST file, gzip got a pathetic 4.7:1. Jules may not have had sufficiently random data, may have had a different file size, or used different settings, or whatever.
Weird ideas, man.
hahahahahahaha! Man, James Sweet, you kill me! hahahahahaha! Your description makes sense and has me with the biggest s*t-eating grin on my face since I got married. Thank you, thank you, thank you.
And Mark’s point about how a compression function needs to be one-to-one, because otherwise its inverse isn’t a function and you can’t correctly decompress the bit stream, reminds me of a saying that one of my professors had. It went something like, “I can compress a file down to one bit. It’s just the decompression that becomes difficult at that point.”
Well, take a file A and compress it to 50KB, assuming that is the smallest it can get to
Then take a file B and compress it to 50KB, assuming that is the smallest it can get to
Then take a file C, which is nothing more than a concatenation of A and B, so compressing that to 50 KB would make me think either A or B alone could be compressed to something smaller then 50 KB, but his algoritm cannot do that…
I remember an organization I belonged to once had a large controversy erupt internally over similar “I CAN COMPRESS ANYTHING D00DZ!” claims, but not the way you think.
The issue is that someone had posted a challenge to anyone making such a claim that ran something like this: (fudging the details because I don’t remember all of them)
1) Claimant will send challenger a claim like this, a number N between 2,000,000 and 10,000,000, and (separately) a ten dollar bill. (or maybe it was $10 through paypal)
2) Challenger will send claimant a file N bytes long.
3) Claimant will then send challenger a statically-linked decompression binary and a compressed data file that when fed to that decompression binary decompresses to the file sent in step (2). The decompression binary and the data file must total together to fewer than 0.99*N bytes.
4) On completion of step (3), challenger sends claimant $1000.
The internal controversy was that the challenger used his organization-affiliated email address to post this challenge publicly, and to receive claims. The internal controversy was whether taking advantage of rubes in this fashion was tarnishing the organization’s reputation enough that some sort of reprimand should be issued about inappropriate use of {organization}.org email addresses.
If the challenger only makes you compress one file, you can write a decompression algorithm that only targets that single file. I’m having some trouble thinking up the specifics, but shouldn’t someone be a $1000 richer by now?
Notice that the size of the binary was included in the total size. If the Kolmogorov complexity of the challenger’s data is greater than 0.99*data, then the claimant will necessarily fail the test.
Even if the claimant was an omniscient god, this would be a good bet for the challenger. The chance of a randomly generated sequence having a relative Kolmogorov complexity of at least 99% is far better than the 10:1000 odds required to make this a fair bet.
Notice that the size of the binary was included in the total size.
Ah but there’s also data in the filenames, the file lengths, and file timestamps. I’ve seen a similar challenge where a claimant was able to “compress” random data by smuggling extra information in via file lengths. There was talk of lawyers before things settled down.
Well, I’m possibly not remembering all the details fully; I think there was something about maximum file name lengths.
Even with the smallest possible “N” value, there’s 20,000 bytes of information you need to catch up. You’re not going to be able to get all those extra bits from the file metadata.
I’m just being pedantic; I’m happy to take it as given that the details were locked down in the contest Daniel refers to.
> if you had some semi-mystical concept of how compression worked (like reducing the space between the bits)
Well, this is a reasonable description run-length encoding — and RLE is consistent with the timeframe you’re talking about. It’s simple enuf that you’re average disk controller used to do it.
E.g.: http://books.google.com/books?id=xfYMoFsX3vsC&pg=PA65&lpg=PA65&dq=RLE+hard+disk+controller&source=bl&ots=PmHo1cMFgV&sig=6FL0jLzZYTP0_BSFf4YXUzQiyjs&hl=en&ei=VbpYTMKpIIHSsAOj7tXSCw&sa=X&oi=book_result&ct=result&resnum=9&ved=0CD0Q6AEwCA#v=onepage&q=RLE%20hard%20disk%20controller&f=false
If you have time, can you please explain “Every proof is dependent on its basic premises. If those premises turn out to be false, then the proof is also false.”
I have another problem I’m thinking about that uses “dependent”, and I’m trying to define “dependent”, and maybe your “dependent” will shed some light on their “dependent”.
Maybe I’m being lazy, but I have to go, and you might can explain it a lot faster than me working it all out. To formalize your sentence, I’m starting off along tracks like this:
A –> B
not A
———-
not(A–>B) (A and not-B)
which is not true, although I need to do the truth table.
Thanks.
Okay, well, my interpretation is that if B is dependent on A, then “dependent” is a synonym for “necessary”, which means that [not A –> not B].
So, initially, what someone claimed to have proved is [A implies B]. However, they then found out that [not A].
Consequently, because [not A implies not B], then we get:
not A implies not B
not A
—————–
not B.
I assume that “the proof is false” means that we’ve proved that B is false, when we initially believed that it was true.
Please pardon me for the elementary exercise and elementary notation, but that’s the format that’s being used by another person, and it’s actually good to occasionally review the basics.
I’m cluttering up things, and I can’t edit my comments.
If B is dependent on A, then I translate that “A is necessary for B”, so in the standard language of implications, this gives us [not A implies not B].
What strikes me as hilarious is that this person is cobbling together a system made out of calls to compression libraries (which he does not understand) and supposes that he can use them as building blocks to make something better than the raw libraries themselves. You use the “re-inventing the wheel” metaphor: you can assemble someone else’s wheels together to build a car, but you cannot generally assemble someone else’s wheels together to build a better wheel.
I think I like this blog.
Okay, you didn’t say that the conclusion of a proof with a premise of A is false if we find out that instead of A, we have not-A. You said that the complete proof is false, so somehow I have to treat the initial proof (which assumes A) as a logical statement, but I give up.
I’ll do the easy part: Assume P is a valid proof that has A has as a hypothesis, and also assume not-A…
It’s probably a simple contradiction of some type, but you’re welcome to delete these 4 comments.
RA, you’re right: Mark misspoke.
Every proof goes from premises to conclusions. If the premises are false, then the conclusions are not necessarily true, but the proof is still valid.
If I have a proof of the statement “If P then Q”, then it’s always true that if P is true then Q is true. If P is false, though, that doesn’t mean that the proof isn’t true. What it means is that we can’t use this proof to conclude that Q is true.
John, thank you very much. I have your blog in my RSS reader. Most of what your write is above my level, so I don’t read much of it, although in 2 to 3 years I may be far enough to begin to appreciate what your write.
What you’re saying is helping me review some definitions, and drive some points home.
I define proof as “valid argument”, and an argument is valid if the conclusion necessarily follows from the premises, or in other words, if the argument is a tautology.
If we assume proof P is a valid argument which assumes A in the premise (and assumes the truth of P is also dependent on A), then there’s nothing that can change the fact that the form of P is a tautology. (Basically, I’m repeating what you say above.)
However, it could be that what Mark means is that if we substitute not-A in place of A in our original argument, then the argument becomes false. Now it becomes a matter of defining what false means. Does false mean “not a tautology”, or does it mean “contradiction”? It’s not obvious to me that it would be a contradiction, or even a not-a-tautology.
What I’m really trying to figure out is the definition of “B is logically dependent on A”.
I’m on Mark’s site because logic and first-order logic fall under the specialty of computer science. He probably won’t respond to me, since I’m a nobody, but because you’re a somebody, he might feel compelled to respond to you.
Please come back in a day (or two) to at least take a brief look at my thoughts on “logically dependent”. From what I can tell, there’s no standard definition. I started this here, since it’s related to the post, but I’ll definitely keep your http://www.formspring.me/DrMathochist page in mind now. It didn’t occur to me until now to use it to get access to a mathematician who has broader knowledge of math than most PhDs.
Test of LaTeX: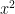 .
.
It’s partly a matter of determining what we mean by “a proof”. Here’s a concrete example that should make things a little clearer.
Many computer science Ph.D.s have been granted for results that essentially state “if P = NP, then X”, and many others have been granted for results that essentially state “if P != NP, then Y”. So, let’s say that someone manages to solve the P-vs.-NP problem one way or the other. Does one of these groups of results suddenly become wrong, and all those Ph.D.s invalid?
Another example: everyone in first-order logic agrees that “a false statement implies any statement”. That is, “F => Z” is automatically true, no matter what the truth value of Z is. That is, there is always a proof that starts from the premise “False” and concludes Z.
The catch — and what Mark was getting at — is that this doesn’t make Z true. It just means that if you could prove False (you can’t) then you could get a proof of Z. Similarly, having a proof that “if P = NP then X” doesn’t mean make X true. It just means that if you could prove P = NP then you could get a proof of X.
In the example he gives, the (hidden) premise is “bandwidth on a telephone line is accurately represented by this mathematical model”. The existence of 1200-baud modems doesn’t mean that the proof was wrong; it means that either the proof was wrong or the premise was wrong. In this case, the proof was fine, but the premise was wrong.
It should also be noted that disproving a premise doesn’t disprove the conclusion, it just invalidates the given argument. Another valid proof from true premises may manage to prove the same conclusion.
Informal language, it hurts me so bad sometimes.
It makes sense. I think I got it. “The proof is false” merely means that we didn’t prove what we claimed to have proved.
Of course, after the sentence I wrote above, I referenced Mark’s post again, and I read,
And I thought, “Was that there all along?”
So because I don’t care about compression, and was totally locked onto “dependent” in one of the paragraphs before that, I didn’t read past the sentence I quoted in my first comment. Consequently, I’ve wasted a certain amount of people’s time here, but I’ve gotten something extra out of your replies that I wouldn’t otherwise have gotten, and also the idea of using your question page. Thanks.
As a child of about 10, I used to try and think of ways to achieve such “free” compression.
As a 25 year old former mathematics and computer science student, I have a thorough understanding of the concept of Kolmogrov complexity, and the impossibility of ideal compression schemes.
As a person with Bipolar Disorder who struggles with psychosis and occasionally emails unsolicited far-fetched ideas to people who probably have better things to do with their time, I suggest getting frustrated with a crank, calling him an idiot and publishing a mathematical proof refuting his self-delusions probably achieves little.
A polite “Unfortunately your scheme will never work, if you can’t understand why I don’t have any more energy to explain it to you, if you think you honestly understand the issue better than computer scientists I suggest seeking the help of a mental mental health professional, and I’m afraid I will have to instantly delete all message from you in the future ” would be my suggestion.
That’s the most intelligent post on this topic so far.
The “one-to-one” correspondence between uncompressed and compressed data is an excellent start. But, the classic “reductio ad absurdum” ought to be good enough to illustrate this to most people.
If you can always compress a file (by at least one bit), then decompress the result, there are at most two files in the universe. The file that a single 1 uncompresses to and the one that a single 0 uncompresses to. Since this is demonstrably not the case, we cannot compress all files.
Do I really need to go through this again? Argh!
Nope.
You don’t have to go through it again for your sane readers, because you already covered it.
You don’t have to go through it again for Jules, because he’s impervious to argument. You have as much chance of convincing him as PZ Myers has of convincing William Dembski.
The correct solution is to block him from your email and blog. Let him go bother someone else.
Someone Is Always Wrong On The Internet, and life’s too short to waste time on the ones who’ve proved they can’t learn. Let him go.
Sigh. A preview option would be nice. Everyone, please pretend I closed “Always” with a </b>.
I’ve got an awesome compression method that turns Jules Gilbert’s blatherings into eight bytes with no loss of information. The output of this method is “BULLSHIT” 🙂
A few years ago I wrote a humorous (ie, fake) encryption algorithm that has great compression as a side effect. Perhaps some of you might get a kick out of it:
Cipher2000
Encryption for the 20th Century!
Fast, Efficient, Friendly
1) Organize your plaintext into a queue of bits. They should represent your plaintext and not be just a bunch of random bits – that would be silly. Calls this queue IQ for Input Queue.
2) Setup a queue for the bits of your ciphertext. This queue should be empty to start. Well, you can keep things other than bits in the queue. Bacon, root beer, sandwich condiments are OK; just no bits. Calls this queue OQ for Output Queue.
3) Pop a bit off of your IQ.
4a) If you got a zero bit, you need to change it to something else. (If you left it the same, your ciphertext would looks suspiciously like your plaintext.) So, pick a random bit value other than zero. Push this new bit onto your OQ. Goto step 5.
4b) If you got a one bit in step 3, keep it exactly the same. The attackers are going to expect you to encrypt all of the bits; so, we’ll keep the one bits the same to throw them off. Push the bit onto your OQ.
5) If your IQ is not empty, loop back to step 3.
6) Now we will validate the results of steps 3-5. Are there any zero bits in your OQ? If so, you need to finish getting your high school diploma; after all, this is not hard math.
7) Since your OQ is full of nothing but one bits (or popsicle sticks, mushrooms, etc.), we can use very effective compression. You don’t even need to count the number of one bits; they are all one bits.
8) Your ciphertext is “All One (1) Bits.”
9) Send that simple message to whomever needs the original data. They can just reverse the process that you used. (If they are having trouble figuring out which bits are which, just send them the plaintext too. That should help a lot.)
All Rights Reserved.
Oops, that smiley is supposed to be the “8” and “)” of step eight.
Mark, just to let you know, the categories on your blog don’t seem to work anymore. I think they didn’t carry over properly when you moved from Scienceblogs.
Fine. I’ll go through this again. Total compression, every time, perfect indisputable algorithm:
Take a file, express it in binary. Take all the ones, bring them to the front, and count them up. Store this number. The zeros are all just zero. Discard them.
Your compressed file is the number. Note that this is recursive.
So everything compresses to 1 bit, except 0 which compresses itself into oblivion. That sounds… like a…. good idea.
Have fun doing the reverse process: Iteratively step through every bit of the compressed data and about 50% of the time add a 0 based on a simple random function.
If he doesn’t care about the reverse process (and he obviously doesn’t), then he could do WAY better: also throw away all ‘1’ bits!
Voila: THE perfect compression algorithm! Compresses ANY file to exactly zero bytes!
Decompression is going to be a bitch though.
I think its kind of interesting that the powerset of a set S has cardinality 2^n where n is the cardinality on S.
So this guy is trying to build a one to one and onto function from P(S) to S and back.
so essentially he’s trying to disprove Cantor =p
I never thought of it that way, but yeah, Compression crackpots are in theory the same as Cantor crackpots!
Actually, he’s trying to map from S, the set of all binary strings (which of course is naturally isomorphic with P(Z) and [0,1]), to a smaller subset of S . In this guys particular case, indeed a finite subset, namely members of S of length less than or equal to 400,000.
Ultimately its actually worse than standard Cantor misinterpretation; compression arguments imply you can get biject the entire Contiuum not just with Z but in fact with {0, 1}, as Ingvar’s neat reductio demonstrates. The absurdity is masked slightly in this particular case by the 50 KB limit, but of course the set of 50 KB files is just as finite as the set of 1 bit files.
You don’t need to understand Cantor’s theorem or Power sets to see that finite sets can’t be in one to one correspondence with larger finite sets and hence by induction with infinity. Even the ancients understood that much.
I’m surprised no one has nitpicked this yet. Far be it for me to let a good nit go unpicked, so…
The above-quoted text is true but it’s not relevant to lossless compression: if I’m trying to compress a file with N bits, I want to produce an output file with at most N-1 bits. So the output it N-2 bits long? Even better!
The set of files of at most N-1 bits has (2^N) – 1 members; since this is less than 2^N, no perfectly lossless compression is possible.
We have that Mark says, “Every proof is dependent on its basic premises.”
I exploit the presence of the word “dependent” to make the claim that my comment here is on-topic, although Mark’s use of “dependent” tends to substantiate my 4 to 6 hours of research that there is no standard definition for “dependent” in the context of logic. That is, I’ve found no definition to definitively tell me what a statement such as “Q is dependent on P” means, which is obviously different from how Mark is using the word.
I seek to define “logical dependence”, or have someone point me to a book or web page where it’s defined. I post this comment here as an attempt to gain some kind of review to make sure that I’m not totally off track. I’ll try to keep things as short as possible.
I haven’t made it through a good first-order logic book, although I have one on my list of books to study. In searching the logic books I have, and searching the web with variations of “logical dependence” or “logically independent”, I find “dependent” all over the place, but I find no standard definition for “logical dependence”, and I’m led to believe that “logical dependence” has to be specifically defined for a particular context.
From the first paragraph of http://en.wikipedia.org/wiki/Logical_connective , I get the basic vocabulary I need.
To say that Q is dependent on P is to say that the truth value of Q depends on the truth value of P. From the same paragraph, I also get that to create logical dependencies, we must use connectives.
To create a logical dependency such that the truth value of Q is dependent on the truth value of P, we must have at least one of the four following possibilities:
1) If P is true then Q must be true.
2) If P is true then Q must be false.
3) If P is false then Q must be true.
4) If P is false then Q must be false.
We have the following connectives to use with two logical statements P and Q: not, implication, and, or, biconditional.
We cannot create any logical dependency between P and Q using only combinations of not, and, or. The very simplest dependence we can create between P and Q is by using one of the following statements:
1) P –> Q
2) Q –> P.
These two statements correspond to statements 1 and 4 above.
My conclusion is that if a person states that “Q is dependent on P”, yet the person doesn’t define what the dependence is, then certain proofs using P and Q cannot be shown, in general, to be valid. Such proofs end up being not well-defined.
Please comment, if you care to, or point me in the right direction, if you care to.
From http://en.wikipedia.org/wiki/Independence_%28mathematical_logic%29 , which references Monk’s “Mathematical Logic”.
So Q is dependent on P if P can be used to prove or falsify T.
What a hassle. I have to think for myself and figure out if I can get a more informal definition from Monk’s definition 22.5 on page 370, without having worked through a formal logic book. Since most everybody in the academic world uses informal logic, you’d think that “independence” would make it into a book along the lines of Rosen’s “Discrete Math” or Bloch’s “Proofs and Fundamentals”. But no.
Honestly it’s not even worthy of a response unless this guy can show a string of 0’s and 1’s as input, then show the output, then show this output as another input, etc.
It’s ridiculous and quite obviously defies all logic.
That said, it’s easy for me to ignore him because he’s not harassing me. Let’s assume for the sake of argument that he has indeed come up with an algorithm that allows him to compress A, produce B as unique output, then compress it further and produce C as unique output, then D, then E, etc. What I would then know about the process is:
– The compression routine obviously is not optimized. If it would, it would go straight from A to Z in one step without all the intermediate steps.
– This would be pretty neat but useless for production environments. If every Pn produces a Pn+1, then what would the return trip look like? If I need to recover a file that is in deep archive, I would then need to go through a many step process from (example) P100 > P99 > P98 > … > P0. How would I know when to stop? (As an aside, this process, if possible, would necessitate somehow encoding the number of times it has gone through the encoding process into the file or it would have to store this metadata outside the file. Either way, it must be stored — so that’s generating more bytes, not less.)
So even if it were possible, which it’s not, it would be hopelessly impractical.
OMG DUDES I have the aw3som3 kompresor!
Sort all the zeroes to the front, then all the ones to the back! Then RLE compress!
So.. did he write a decompressor yet?
“Just about every other computer scientist in the whole wide world believes this is impossible”
every other? In that statement alone he’s off by a factor of ‘just about’ 2!
I noticed that the original mail from the CI talks at length about compressing things, but nowhere does it actually indicate that he has ever *decompressed* anything.
I think he’s having an extended yank on your chain.
If he really doesn’t care about reversing the compression, then perhaps he should be using a SHA-1 compression, or an MD-5 compression … 😉
1. the new place seems to be great!
2. To add to your zoo of idiots: here you can find Andrew Schlafly (son of Phyllis Schlafly, creator of Conservapaedia) showing that The British are notoriously weak in mathematics – a fun thing to share with colleagues in the U.K.
3. Above this, you’ll find a textbook example of selection bias.
4. can you add a preview-option? Pretty please?
If you compressed the entire universe to a single binary digit, would that bit be 1 or 0?
Yes.
It might be just quicker to say that lossless data compression is impossible.
But it would be more accurate to say that effective data compression requires knowledge of what specific types of redundancy is in the data being compressed. Thankfully, a huge amount real-world data that we wish to compress all exhibit similar types of redundancy.
Yes. What I was trying to point, and what seems to be the source of all compression idiocy, was that if you look at all bit patterns of length N, there is no redundancy in them. Any lossless compression algorithm is just a means of computing the invertible mapping from bit-pat-N -> bit-pat-N. Nothing lost, nothing gained.
The only reason compression is useful and seems like something is being compressed is that we are interpreting the bit-pat-N within a frame that allows calling only some of them meaningful while the rest is considered garbage.
All compression idiocy seems to happen in the space of interpretation and doesn’t really touch the actual compression algorithm (mapping) at all.
So if instead of using the word “compression” a choice had been made to use “flying monkeys”, with some luck, there would be flying monkey idiocy where the monkeys would be able to supplant parts of the bit patterns. Or, something similar…
I recommend the classic EB White short story “Irtnog.”
This guy reminds me of all those who claim to have refuted Goedel’s incompleteness theorem by finding a flaw in the reflexive character of the proof. What rubbish.