I’ve written about intuitionistic logic before. In fact, there’s a whole section about it in my book. But now that I’m reading a lot about type theory, I’m starting to look at it diferently.
When you study classical axiomatic set theory, you’re necessarily also studying classical first order predicate logic. You have to be doing that, because classical axiomatic set theory is deeply and intimately intertwined with FOPL. Similarly, the semantics of FOPL as it’s used in modern math are inextricably tangled with set theory. Sets are specified by predicates; predicates get their meaning from the sets of objects that they satisfy.
You can view type theory – or at least Martin-Loff’s intuitionistic type theory – as having nearly the same relationship to intuitionistic logic. We’ll see that in detail in later posts, but for now, intuitionistic type theory is a fundamental mathematical framework which is built on intuitionistic logic. So you can’t talk about this kind of type theory unless you understand the basics of the logic.
In this post, I’m going to try to explain what intuitionistic logic is, and how it differs from FOPL. (We’ll see all of this in more detail later.)
Intuitionistic logic is a modal predicate logic, which is built around a constructivist idea of truth. The intuitionistic idea of truth ends up being much stronger than what most of us are used to from standard FOPL: it means that nothing exists unless there is a concrete way of constructing it.
For a concrete example of what that means: in standard FOPL with the ZFC axioms, you can prove the Banach-Tarski paradox. Banach-Tarski (which I wrote about HERE) says that it’s possible to take a sphere the size of an orange, cut it into pieces, and then re-assemble those pieces into two spheres the same size as the original orange. Or, alternatively, that you can take those pieces that you sliced an orange-sized sphere into, and re-assemble them into a sphere the size of the sun.
Many people would say that this is, clearly, ridiculous. Others would point out a variety of rationalizations: that a sphere the size of an orange and a sphere the size of the sun contain the same number of points; or that the slicing process transitioned from a metric topology to a collection of non-metric topologies, or several other possible explanations.
But what no one can dispute is that there is one very important property of this proof. Those slices are unconstructable. That is, they exist based on a proof using the axiom of choice, but the sets of points in those topologies can’t be constructed by any process. They exist as a necessary implication of the axiom of choice, but we can’t construct them, and even given a pair of sets, one of which is one of those slices, and one of which isn’t, we can’t identify which one is.
According to intuitionism, this is ridiculous. Saying that something exists, but that it is forever beyond our reach is foolishness. If we can’t construct it, if we can’t describe how to identify it, what does it mean to say that it must exist?
When you’re working in intuitionistic logic, every proof that a type of thing exists consists of either a concrete example of the thing, or a process for constructing an example of the thing. A proof of a negative is a concrete counterexample, or a process for creating one. In computer-sciency-terms, the process doesn’t need to terminate. You don’t have to be able to construct something in finite time. But you need to have a process that describes how to contsruct it. So you can, for example, still do Cantor’s diagonalization in intuitionistic logic: if someone gives you an alleged complete 1:1 mapping between the real numbers and the integers, the proof tells you how to create a counterexample. But you can’t do the proof of Banach-Tarski, because it relies on an axiom-of-choice existence proof of something non-constructable.
The way that intuitionistic logic creates that constructivist requirement is not what you might expect. When I first heard about it, I assumed that it was based on a statement of principle: a proof has to create a concrete example. But that approach has an obvious problem: how do you mathematically define it? Logic is supposed to be purely symbolic. How can you take an abstract statement about what a proof should be, and make it work in logic?
Logic is built on inference rules. You have a collection of statements, and a collection of rules about how to use those statements to produce proofs. It turns out that by making a couple of simple changes to the rules of inference that you can get exactly the constructivist requirements that we’d want. It’s based on two real changes compared to standard FOPL.
Intuitionistic logic is modal. In FOPL, any given statement is either true or false. If it’s not true, then it’s false. If it’s true, it’s always true, and always was true. There’s no other choice. In intuitionistic logic, that’s not really the case: intuitionistic logic has three states: true, false, and unknown. If you know nothing about it, then it’s formally unknown, and it will stay unknown until there’s a proof about it; once you find a proof, it’s truth value changes from unknown to either true or false. All of the inference rules of intuitionistic logic only allow inference from proven statements. You can’t reason about an unknown – you need to have a proof that moves it from unknown to either true or false first.
The semantics of this are quite simple: it’s a tiny change in the definition of truth. In FOPL, a statement is true if there exists a proof of that statement, and it’s false if there’s a proof of the negation of that statement. In intuitionistic logic, a statement is true if you have a proof of that statement; and it’s false if you can prove that there is no proof of the statement If you haven’t proven , then is unknown. If is unknown, then is also unknown. is, similarly, not true until you have a proof of either or : it means that either “There is a proof of A or there is a proof of “. But if we don’t know if there’s a proof of either one, then it’s unknown! You could argue that this is true in FOPL as well – but in FOPL, you can rely on the fact that , and you can use that in a proof, and explore both options. In intuitionistic logic, you can’t: you can’t do anything with until you’ve got a proof.
It’s amazing how small the change to FOPL is to produce something that is so strongly constructionist. The easiest way to appreciate it is to just look at the rules, and how they change. To do that, I’m going to quickly walk through the inference rules of intuitionistic logic, and then show you what you’d need to change to get classical FOPL. Most of the time, when I’ve written about logics, I used sequents to write the inference rules; for ease of typesetting (and for the fun of doing something just a bit different), this time, I’m going to use Hilbert calculus (the same method that Gödel used in his incompleteness proof.) In HC, you define axioms and inference rules. For intuitionistic logic, we need to define three inference rules:
Modus Ponens: Given and , you can infer .
Universal Generation: Given , you can infer if is not free in .
Existential Generation: Given , you can infer , if is not free in .
With the inference rules out of the way, there’s a collection of axioms. Each axiom is actually a schema: you can substitute any valid statement for any of the variables in the axioms.
Then-1: .
Then-2:
And-1:
And-2:
And-3:
Or-1:
Or-2:
Or-3:
False: . (For a bit of explanation, this rule means that we don’t need to have rules – can be treated as .)
Universal: , if is not bound by instantiating .
Existential: if is not bound by instantiating .
That’s intuitionistic logic. What’s the difference between that and FOPL? What kinds of powerful reasoning features did you need to give up from FOPL to get this strongly constructivist logic?
Just one simple axiom: the law of the excluded middle, .
That’s it. Get rid of the excluded middle, and you’ve got the beautiful constructivist intuitionistic logic. All we had to give up is one of the most intuitionnally obvious rules in all of logic.
After a bit of a technical delay, it’s time to finish the repost of incompleteness! Finally, we’re at the end of our walkthrough of Gödel great incompleteness proof. As a refresher, the basic proof sketch is:
Take a simple logic. We’ve been using a variant of the Principia Mathematica’s logic, because that’s what Gödel used.
Show that any statement in the logic can be encoded as a number using an arithmetic process based on the syntax of the logic. The process of encoding statements numerically is called Gödel numbering.
Show that you can express meta-mathematical properties of logical statements in terms of arithemetic properties of their Gödel numbers. In particular, we need to build up the logical infrastructure that we need to talk about whether or not a statement is provable.
Using meta-mathematical properties, show how you can create an unprovable statement encoded as a Gödel number.
What came before:
Gödel numbering: The logic of the Principia, and how to encode it as numbers. This was step 1 in the sketch.
Arithmetic Properties: what it means to say that a property can be expressed arithemetically. This set the groundwork for step 2 in the proof sketch.
Encoding meta-math arithmetically: how to take meta-mathematical properties of logical statements, and define them as arithmetic properties of the Gödel numberings of the statements. This was step 2 proper.
So now we can move on to step three, where we actually see why mathematical logic is necessarily incomplete.
What I did in the last post was walk through a very laborious process that showed how we could express meta-mathematical properties of logical statements as primitive recursive functions and relations. Using that, we were able to express a non-primitive-recursive predicate provable, which is true for a particular number if and only if that number is the Gödel number representation of a statement which is provable.
pred provable(x) =
some y {
proofFor(y, x)
}
}
The reason for going through all of that was that we really needed to show how we could capture all of the necessary properties of logical statements in terms of arithmetic properties of their Gödel numbers.
Now we can get to the target of Gödel’s effort. What Gödel was trying to do was show how to defeat the careful stratification of the Principia’s logic. In the principia, Russell and Whitehead had tried to avoid problems with self-reference by creating a very strict type-theoretic stratification, where each variable or predicate had a numeric level, and could only reason about objects from lower levels. So if natural numbers were the primitive objects in the domain being reasoned about, then level-1 objects would be things like specific natural numbers, and level-1 predicates could reason about specific natural numbers, but not about sets of natural numbers or predicates over the natural numbers. Level-2 objects would be sets of natural numbers, and level-2 predicates could reason about natural numbers and sets of natural numbers, but not about predicates over sets of natural numbers, or sets of sets of natural numbers. Level-3 objects would be sets of sets of natural numbers… and so on.
The point of this stratification was to make self-reference impossible. You couldn’t make a statement of the form “This predicate is true”: the predicate would be a level-N predicate, and only a level N+1 predicate could reason about a level-N predicate.
What Gödel did in the arithmetic process we went through in the last post is embed a model of logical statements in the natural numbers. That’s the real trick: the logic of the principia is designed to work with a collection of objects that are a model of the natural numbers. By embedding a model of logical statements in the natural numbers, he made it possible for a level-1 predicate (a predicate about a specific natural number) to reason about any logical statement or object. A level-1 predicate can now reason about a level-7 object! A level-1 predicate can reason about the set defined by a level-1 predicate: a level-1 predicate can reason about itself!. A level-1 predicate can, now, reason about any logical statement at all – itself, a level-2 predicate, or a level-27 predicate. Gödel found a way to break the stratification.
Now, we can finally start getting to the point of all of this: incompleteness! We’re going to use our newfound ability to nest logical statements into numbers to construct an unprovable true statement.
In the last post, one of the meta-mathematical properties that we defined for the Gödel-numbered logic was immConseq, which defines when some statement x is an immediate consequence of a set of statements S. As a reminder, that means that x can be inferred from statements in S in one inferrence step.
We can use that property to define what it means to be a consequence of a set of statements: it’s the closure of immediate consequence. We can define it in pseudo-code as:
def conseq(κ) = {
K = κ + axioms
added_to_k = false
do {
added_to_k = false
for all c in immConseq(K) {
if c not in K {
add c to K
added_to_k = true
}
}
} while added_to_k
return K
}
In other words, Conseq(κ) is the complete set of everything that can possibly be inferred from the statements in κ and the axioms of the system. We can say that there’s a proof for a statement x in κ if and only if x ∈ Conseq(κ).
We can take the idea of Conseq use that to define a strong version of what it means for a logical system with a set of facts to be consistent. A system is ω-consistent if and only if there is not a statement a such that: a ∈ Conseq(κ) ∧ not(forall(v, a)) ∈ Conseq(κ).
In other words, the system is ω-consistent as long as it’s never true that both a universal statement and it. But for our purposes, we can treat it as being pretty much the same thing. (Yes, that’s a bit hand-wavy, but I’m not trying to write an entire book about Gödel here!)
(Gödel’s version of the definition of ω-consistency is harder to read than this, because he’s very explicit about the fact that Conseq is a property of the numbers. I’m willing to fuzz that, because we’ve shown that the statements and the numbers are interchangable.)
Using the definition of ω-consistency, we can finally get to the actual statement of the incompleteness theorem!
Gödel’s First Incompleteness Theorem: For every ω-consistent primitive recursive set κ of formulae, there is a primitive-recursive predicate r(x) such that neither forall(v, r) nor not(forall(v, r)) is provable.
To prove that, we’ll construct the predicate r.
First, we need to define a version of our earlier isProofFigure that’s specific to the set of statements κ:
pred isProofFigureWithKappa(x, kappa) = {
all n in 1 to length(x) {
isAxiom(item(n, x)) or
item(n, x) in kappa or
some p in 0 to n {
some q in 0 to n {
immedConseq(item(n, x), item(p, x), item(q, x))
}
}
} and length(x) > 0
}
This is the same as the earlier definition – just specialized so that it ensures that every statement in the proof figure is either an axiom, or a member of κ.
We can do the same thing to specialize the predicate proofFor and provable:
pred proofForStatementWithKappa(x, y, kappa) = {
isProofFigureWithKappa(x, kappa) and
item(length(x), x) = y
}
pred provableWithKappa(x, kappa) = {
some y {
proofForStatementWithKappa(y, x, kappa)
}
}
If κ is the set of basic truths that we can work with, then provable in κ is equivalent to provable.
Now, we can define a predicate UnprovableInKappa:
pred NotAProofWithKappa(x, y, kappa) = {
not (proofForKappa(x, subst(y, 19, number(y))))
}
Based on everything that we’ve done so far, NotAProofWithKappa is primitive recursive.
This is tricky, but it’s really important. We’re getting very close to the goal, and it’s subtle, so let’s take the time to understand this.
Remember that in a Gödel numbering, each prime number is a variable. So 19 here is just the name of a free variable in y.
Using the Principia’s logic, the fact that variable 19 is free means that the statement is parametric in variable 19. For the moment, it’s an incomplete statement, because it’s got an unbound parameter.
What we’re doing in NotAProofWithKappa is substituting the numeric coding of y for the value of y‘s parameter. When that’s done, y is no longer incomplete: it’s unbound variable has been replaced by a binding.
With that substitution, NotAProofWithKappa(x, y, kappa) is true when xdoes not prove that y(y) is true.
What NotAProofWithKappa does is give us a way to check whether a specific sequence of statements x is not a proof of y.
We want to expand NotAProofWithKappa to something universal. Instead of just saying that a specific sequence of statements x isn’t a proof for y, we want to be able to say that no possible sequence of statements is a proof for y. That’s easy to do in logic: you just wrap the statement in a “∀ x ( )”. In Gödel numbering, we defined a function that does exactly that. So the universal form of provability is: ∀ a (NotAProofWithKappa(a, y, kappa)).
In terms of the Gödel numbering, if we assume that the Gödel number for the variable a is 17, and the variable y is numbered as 19, we’re talking about the statement p = forall(17, ProvableInKappa(17, 19, kappa).
p is the statement that for some logical statement (the value of variable 19, or y in our definition), there is no possible value for variable 17 (a) where a proves y in κ.
All we need to do now is show that we can make p become self-referential. No problem: we can just put number(p) in as the value of y in UnprovableInKappa. If we let q be the numeric value of the statement UnprovableInKappa(a, y), then:
r = subst(q, 19, p)
i = subst(p, 19, r)
i says that there is no possible value x that proves p(p). In other words, p(p) is unprovable: there exists no possible proof that there is no possible proof of p!
This is what we’ve been trying to get at all this time: self-reference! We’ve got a predicate y which is able to express a property of itself. Worse, it’s able to express a negative property of itself!
Now we’re faced with two possible choices. Either i is provable – in which case, κ is inconsistent! Or else i is unprovable – in which case κ is incomplete, because we’ve identified a true statement that can’t be proven!
That’s it: we’ve shown that in the principia’s logic, using nothing but arithmetic, we can create a true statement that cannot be proven. If, somehow, it were to be proven, the entire logic would be inconsistent. So the principia’s logic is incomplete: there are true statements that cannot be proven true.
We can go a bit further: the process that we used to produce this result about the Principia’s logic is actually applicable to other logics. There’s no magic here: if your logic is powerful enough to do Peano arithmetic, you can use the same trick that we demonstrated here, and show that the logic must be either incomplete or inconsistent. (Gödel proved this formally, but we’ll just handwave it.)
Looking at this with modern eyes, it doesn’t seem quite as profound as it did back in Gödel’s day.
When we look at it through the lens of today, what we see is that in the Principia’s logic, proof is a mechanical process: a computation. If every true statement was provable, then you could take any statement S, and write a program to search for a proof of either S or ¬ S, and eventually, that program would find one or the other, and stop.
In short, you’d be able to solve the halting problem. The proof of the halting problem is really an amazingly profound thing: on a very deep level, it’s the same thing as incompleteness, only it’s easier to understand.
But at the time that Gödel was working, Turing hadn’t written his paper about the halting problem. Incompletess was published in 1931; Turing’s halting paper was published in 1936. This was a totally unprecedented idea when it was published. Gödel produced one of the most profound and surprising results in the entire history of mathematics, showing that the efforts of the best mathematicians in the world to produce the perfection of mathematics were completely futile.
On to the next part of Gödel’s proof of incompleteness. To refresh your memory, here’s a sketch of the proof:
Take a simple logic. We’ve been using a variant of the Principia Mathematica’s logic, because that’s what Gödel used.
Show that any statement in the logic can be encoded as a number using an arithmetic process based on the syntax of the logic. The process of encoding statements numerically is called Gödel numbering.
Show that you can express meta-mathematical properties of logical statements in terms of arithemetic properties of their Gödel numbers. In particular, we need to build up the logical infrastructure that we need to talk about whether or not a statement is provable.
Using meta-mathematical properties, show how you can create an unprovable statement encoded as a Gödel number.
What we’ve done so far is the first two steps, and part of the third. In this post, we saw the form of the Principia’s logic that we’re using, and how to numerically encode it as a Gödel numbering. We’ve start started on the third point in this post, by figuring out just what it means to say that things are encoded arithmetically. Now we can get to the part where we see how to encode meta-mathematical properties in terms of arithmetic properties of the Gödel numbering. In this post, we’re going to build up everything we need to express syntactic correctness, logical validity, and provability in terms of arithmetical properties of Gödel numbers. (And, as a reminder, I’ve been using this translation on Gödel’s original paper on incompleteness.)
This is the most complex part of the incompleteness proof. The basic concept of what we’re doing is simple, but the mechanics are very difficult. What we want to do is define a set of predicates about logical statements, but we want those predicates to be expressed as arithmetic properties of the numerical representations of the logical statements.
The point of this is that we’re showing that done in the right way, arithmetic is logic – that doing arithmetic on the Gödel numbers is doing logical inference. So what we need to do is build up a toolkit that shows us how to understand and manipulate logic-as-numbers using arithmetic. As we saw in the last post, primitive recursion is equivalent to arithmetic – so if we can show how all of the properties/predicates that we define are primitive recursive, then they’re arithmetic.
This process involves a lot of steps, each of which is building the platform for the steps that follow it. I struggled quite a bit figuring out how to present these things in a comprehensible way. What I ended up with is writing them out as code in a pseudo-computer language. Before inventing this language, I tried writing actual executable code, first in Python and then in Haskell, but I wasn’t happy with the clarity of either one.
Doing it in an unimplemented language isn’t as big a problem as you might think. Even if this was all executable, you’re not going to be able to actually run any of it on anything real – at least not before you hair turns good and gray. The way that this stuff is put together is not what any sane person would call efficient. But the point isn’t to be efficient: it’s to show that this is possible. This code is really all about searching; if we wanted to be efficient, this could all be done in a different representation, with a different search method that was a lot faster – but that wolud be harder to understand.
So, in the end, I threw together a simple language that’s easy to read. This language, if it were implemented, wouldn’t really even be Turing complete – it’s a primitive recursive language.
Basics
We’ll start off with simple numeric properties that have no obvious connection to the kinds of meta-mathematical statements that we want to talk about, but we’ll use those to define progressively more and more complex and profound properties, until we finally get to our goal.
# divides n x == True if n divides x without remainder.
pred divides(n, x) = x mod n == 0
pred isPrime(0) = False
pred isPrime(1) = False
pred isPrime(2) = True
pred isPrime(n) = {
all i in 2 to n {
not divides(i, n)
}
}
fun fact(0) = 1
fun fact(n) = n * fact(n - 1)
Almost everything we’re going to do here is built on a common idiom. For anything we want to do arithmetically, we’re going to find a bound – a maximum numeric value for it. Then we’re going to iterate over all of the values smaller than that bound, searching for our target.
For example, what’s the nth prime factor of x? Obviously, it’s got to be smaller than x, so we’ll use x as our bound. (A better bound would be the square root of x, but it doesn’t matter. We don’t care about efficiency!) To find the nth prime factor, we’ll iterate over all of the numbers smaller than our bound x, and search for the smallest number which is prime, which divides x, and which is larger than the n-1th prime factor of x. We’ll translate that into pseudo-code:
fun prFactor(0, x) = 0
fun prFactor(n, x) = {
first y in 1 to x {
isPrime(y) and divides(y, x) and prFactor(n - 1, x) < y
}
}
Similarly, for extracting values from strings, we need to be able to ask, in general, what's the nth prime number? This is nearly identical to prFactor above. The only difference is that we need a different bound. Fortunately, we know that the nth prime number can't be larger than the factorial of the previous prime plus 1.
fun nthPrime(0) = 0
fun nthPrime(n) = {
first y in 1 to fact(nthPrime(n - 1)) + 1 {
isPrime(y) and y > nthPrime(n - 1))
}
}
In composing strings of Gödel numbers, we use exponentiation. Given integers x and n, xn, we can obviously compute them via primitive recursion. I'll define them below, but in the rest of this post, I'll write them as an operator in the language:
fun pow(n, 0) = 1
fun pow(n, i) = n * pow(n, i - 1)
String Composition and Decomposition
With those preliminaries out of the way, we can get to the point of defining something that's actually about one of the strings encoded in these Gödel numbers. Given a number n encoding a string, item(n, x) is the value of the nth character of x. (This is slow. This is really slow! We're getting to the limit of what a very powerful computer can do in a reasonable amount of time. But this doesn't matter. The point isn't that this is a good way of doing these things: it's that these things are possible. To give you an idea of just how slow this is, I started off writing the stuff in this post in Haskell. Compiled with GHC, which is a very good compiler, using item to extract the 6th character of an 8 character string took around 10 minutes on a 2.4Ghz laptop. In the stuff that follows, we'll be using this to extract characters from strings that could be hundreds of characters long!)
fun item(n, x) = {
first y in 1 to x {
divides(prFactor(n, x) ** y, y) and
not divides(prFactor(n, x)**(y+1), x)
}
}
Given a string, we want to be able to ask how long it is; and given two strings, we want to be able to concatenate them.
fun length(x) = {
first y in 1 to x {
prFactor(y, x) > 0 and prFactor(y + 1, x) == 0
}
}
fun concat(x, y) = {
val lx = length(x)
val ly = length(y)
first z in 1 to nthprime(lx + ly)**(x + y) {
(all n in 1 to lx {
item(n, z) == item(n, x)
}) and (all n in 1 to ly {
item(n + lx, z) == item(n, y)
})
}
}
fun concatl([]) = 0
fun concatl(xs) = {
concat(head(xs), concatl(tail(xs)))
}
fun seq(x) = 2**x
We want to be able to build statements represented as numbers from other statements represented as numbers. We'll define a set of functions that either compose new strings from other strings, and to check if a particular string is a particular kind of syntactic element.
# x is a variable of type n.
pred vtype(n, x) = {
some z in 17 to x {
isPrime(z) and x == n**z
}
}
# x is a variable
pred isVar(x) = {
some n in 1 to x {
vtype(n, x)
}
}
fun paren(x) =
concatl([gseq(11), x, gseq(13)])
# given the Gödel number for a statement x, find
# the Gödel number for not x.
fun gnot(x) =
concat(gseq(5), paren(x))
# Create the number for x or y.
fun gor(x, y) =
concatl([paren(x), seq(7), paren(y)])
# Create the number for 'forall x(y)'.
fun gforall(x, y) =
concatl([seq(9), seq(x), paren(y)])
# Create the number for x with n invocations of the primitive
# successor function.
fun succn(0, x) = x
fun succn(n, x) = concat(seq(3), succn(n - 1, x))
# Create the number n using successor and 0.
fun gnumber(n) = succn(n, seq(1))
# Check if a statement is type-1.
pred stype_one(x) = {
some m in 1 to x {
m == 1 or (vtype(1, m) and x == succn(n, seq(m))
}
}
# Check if a statement is type n.
pred fstype(1, x) = stype_one(x)
pred fstype(n, x) =
some v in 1 to x {
vtype(n, v) and R(v)
}
}
That last function contains an error: the translation of Gödel that I'm using says R(v) without defining R. Either I'm missing something, or the translator made an error.
Formulae
Using what we've defined so far, we're now ready to start defining formulae in the basic Principia logic. Forumlae are strings, but they're strings with a constrained syntax.
pred elFm(x) = {
some y in 1 to x {
some z in 1 to x {
some n in 1 to x {
stype(n, y) and stype(n+1, z) and x == concat(z, paren(y))
}
}
}
}
All this is doing is expressing the grammar rule in arithmetic form: an elementary formula is a predicate: P(x), where x is a variable on level n, and P is a variable of level x + 1.
The next grammar rule that we encode this way says how we can combine elementary formulae using operators. There are three operators: negation, conjunction, and universal quantification.
pred op(x, y, z) = {
x == gnot(y) or
x == gor(y, z) or
(some v in 1 to x { isVar(v) and x == gforall(v, y) })
}
And now we can start getting complex. We're going to define the idea of a valid sequence of formulae. x is a valid sequence of formulae when it's formed from a collection of formulae, each of which is either an elementary formula, or is produced from the formulae which occured before it in the sequence using either negation, logical-or, or universal quantification.
In terms of a more modern way of talking about it, the syntax of the logic is a grammar. A formula sequence, in this system, is another way of writing the parse-tree of a statement: the sequence is the parse-tree of the last statement in the sequence.
pred fmSeq(x) = {
all p in 0 to length(x) {
elFm(item(n, x)) or
some p in 0 to (n - 1) {
some q in 0 to (n - 1) {
op(item(n,x), item(p, x), item(q, x))
}
}
}
}
The next one bugs me, because it seems wrong, but it isn't really! It's a way of encoding the fact that a formula is the result of a well-defined sequence of formulae. In order to ensure that we're doing primitive recursive formulae, we're always thinking about sequences of formulae, where the later formulae are produced from the earlier ones. The goal of the sequence of formula is to produce the last formula in the sequence. What this predicate is really saying is that a formula is a valid formula if there is some sequence of formulae where this is the last one in the sequence.
Rephrasing that in grammatical terms, a string is a formula if there is valid parse tree for the grammar that produces the string.
pred isFm(x) = {
some n in 1 to nthPrime(length(x)**2)**(x*length(x)**2) {
fmSeq(n)
}
}
So, now, can we say that a statement is valid because it's parsed according to the grammar? Not quite. It's actually a familiar problem for people who write compilers. When you parse a program in some language, the grammar doesn't usually specify variables must be declared before they're used. It's too hard to get that into the grammar. In this logic, we've got almost the same problem: the grammar hasn't restricted us to only use bound variables. So we need to have ways to check whether a variable is bound in a Gödel-encoded formula, and then use that to check the validity of the formula.
# The variable v is bound in formula x at position n.
pred bound(v, n, x) = {
isVar(v) and isFm(x) and
(some a in 1 to x {
some b in 1 to x {
some c in 1 to x {
x == concatl([a, gforall(v, b), c]) and
isFm(b) and
length(a) + 1 ≤ n ≤ length(a) + length(forall(v, b))
}
}
})
}
# The variable v in free in formula x at position n
pred free(v, n, x) = {
isVar(v) and isFm(x) and
(some a in 1 to x {
some b in 1 to x {
some c in 1 to x {
v == item(n, x) and n ≤ length(x) and not bound(v, n, x)
}
}
})
}
pred free(v, x) = {
some n in 1 to length(x) {
free(v, n, x)
}
}
To do logical inference, we need to be able to do things like replace a variable with a specific infered value. We'll define how to do that:
# replace the item at position n in x with y.
fun insert(x, n, y) = {
first z in 1 to nthPrime(length(x) + length(y))**(x+y) {
some u in 1 to x {
some v in 1 to x {
x == concatl([u, seq(item(n, x)), v]) and
z == concatl([u, y, v]) and
n == length(u) + 1
}
}
}
}
There are inference operations and validity checks that we can only do if we know whether a particular variable is free at a particular position.
# freePlace(k, v, k) is the k+1st place in x (counting from the end)
# where v is free.
fun freePlace(0, v, x) = {
first n in 1 to length(x) {
free(v, n, x) and
not some p in n to length(x) {
free(v, p, x)
}
}
}
fun freePlace(k, v, x) = {
first n in 1 to freePlace(n, k - 1, v) {
free(v, n, x) and
not some p in n to freePlace(n, k - 1, v) {
free(v, p, x)
}
}
}
# number of places where v is free in x
fun nFreePlaces(v, x) = {
first n in 1 to length(x) {
freeplace(n, v, x) == 0
}
}
In the original logic, some inference rules are defined in terms of a primitive substitution operator, which we wrote as subst[v/c](a) to mean substitute the value c for the variable c in the statement a. We'll build that up on a couple of steps, using the freePlaces function that we just defined.
# Subst1 replaces a single instance of v with y.
fun subst'(0, x, v, y) = x
fun subst1(0k, x, v, y) =
insert(subst1(k, x, v, y), freePlace(k, v, x), y)
# subst replaces all instances of v with y
fun subst(x, v, y) = subst'(nFreePlaces(v, x), x, v, y)
The next thing we're going to do isn't, strictly speaking, absolutely necessary. Some of the harder stuff we want to do will be easier to write using things like implication, which aren't built in primitive of the Principia logic. To write those as clearly as possible, we'll define the full suite of usual logical operators in terms of the primitives.
# implication
fun gimp(x, y) = gor(gnot(x), y)
# logical and
fun gand(x, y) = gnot(gor(gnot(x), gnot(y)))
# if/f
fun gequiv(x, y) = gand(gimp(x, y), gimp(y, x))
# existential quantification
fun gexists(v, y) = not(gforall(v, not(y)))
Axioms
The Peano axioms are valid logical statements, so they have Gödel numbers in this system. We could compute their value, but why bother? We know that they exist, so we'll just give them names, and define a predicate to check if a value matches them.
The form of the Peano axioms used in incompleteness are:
const pa1 = ...
const pa2 = ...
const pa3 = ...
pred peanoAxiom(x) =
(x == pa1) or (x == pa2) or (x == pa3)
Similarly, we know that the propositional axioms must have numbers. The propositional
axioms are:
I'll show the translation of the first - the rest follow the same pattern.
# Check if x is a statement that is a form of propositional
# axiom 1: y or y => y
pred prop1Axiom(x) =
some y in 1 to x {
isFm(x) and x == imp(or(y, y), y)
}
}
pred prop2Axiom(x) = ...
pred prop3Axiom(x) = ...
pred prop4Axiom(x) = ...
pred propAxiom(x) = prop2Axiom(x) or prop2Axiom(x) or
prop3Axiom(x) or prop4Axiom(x)
Similarly, all of the other axioms are written out in the same way, and we add a predicate isAxiom to check if something is an axiom. Next is quantifier axioms, which are complicated, so I'll only write out one of them - the other follows the same basic scheme.
The two quantifier axioms are:
quantifier_axiom1_condition(z, y, v) = {
not some n in 1 to length(y) {
some m in 1 to length(z) {
some w in 1 to z {
w == item(m, z) and bound(w, n, y) and free(v, n, y)
}
}
}
}
pred quantifier1Axiom(x) = {
some v in 1 to x {
some y in 1 to x {
some z in 1 to x {
some n in 1 to x {
vtype(n, v) and stype(n, z) and
isFm(y) and
quantifier_axiom1_condition(z, y, v) and
x = gimp(gforall(v, y), subst(y, v, z))
}
}
}
}
}
quanitifier_axiom2 = ...
isQuantifierAxiom = quantifier1Axiom(x) or quantifier2Axiom(x)
We need to define a predicate for the reducibility axiom (basically, the Principia's version of the ZFC axiom of comprehension). The reducibility axiom is a schema: for any predicate , . In our primitive recursive system, we can check if something is an instance of the reducibility axiom schema with:
pred reduAxiom(x) =
some u in 1 to x {
some v in 1 to x {
some y in 1 to x {
some n in 1 to x {
vtype(n, v) and
vtype(n+1, u) and
not free(u, y) and
isFm(y) and
x = gexists(u, gforall(v, gequiv(concat(seq(u), paren(seq(v))), y)))
}
}
}
}
}
Now, the set axiom. In the logic we're using, this is the axiom that defines set equality. It's written as . Set equality is defined for all types of sets, so we need to have one version of axiom for each level. We do that using type-lifting: we say that the axiom is true for type-1 sets, and that any type-lift of the level-1 set axiom is also a version of the set axiom.
fun typeLift(n, x) = {
first y in 1 to x**(x**n) {
all k in 1 to length(x) {
item(k, x) ≤ 13 and item(k, y) == item(k, v) or
item(k, x) > 13 and item(k, y) = item(k, x) * prFactor(1, item(k, x))**n
}
}
}
We haven't defined the type-1 set axiom. But we just saw the axiom above, and it's obviously a simple logical statement. That mean that it's got a Gödel number. Instead of computing it, we'll just say that that number is called sa1. Now we can define a predicate to check if something is a set axiom:
val sa1 = ...
pred setAxiom(x) =
some n in 1 to x {
x = typeLift(n, sa)
}
}
We've now defined all of the axioms of the logic, so we can now create a general predicate to see if a statement fits into any of the axiom categories:
pred isAxiom(x) =
peanoAxiom(x) or propAxiom(x) or quantifierAxom(x) or
reduAxiom(x) or setAxiom(x)
Proofs and Provability!
With all of the axioms expressible in primitive recursive terms, we can start on what it means for something to be provable. First, we'll define what it means for some statement x to be an immediate consequence of some statements y and z. (Back when we talked about the Principia's logic, we said that x is an immediate consequence of y and z if either: y is the formula z ⇒ x, or if c is the formula ∀v.x).
pred immConseq(x, y, z) = {
y = imp(z, x) or
some v in 1 to x {
isVar(v) and x = forall(v, y)
}
}
Now, we can use our definition of an immediate consequence to specify when a sequence of formula is a proof figure. A proof figure is a sequence of statements where each statement in it is either an axiom, or an immediate consequence of two of the statements that preceeded it.
pred isProofFigure(x) = {
(all n in 0 to length(x) {
isAxiom(item(n, x)) or
some p in 0 to n {
some q in 0 to n {
immConseq(item(n, x), item(p, x), item(q, x))
}
}
}) and
length(x) > 0
}
We can say that x is a proof of y if x is proof figure, and the last statement in x is y.
pred proofFor(x, y) =
isProofFigure(x) and
item(length(x), x) == y
Finally, we can get to the most important thing! We can define what it means for something to be provable! It's provable if there's a proof for it!
pre provable(x) =
some y {
proofFor(y, x)
}
}
Note that this last one is not primitive recursive! There's no way that we can create a bound for this: a proof can be any length.
At last, we're done with these definition. What we've done here is really amazing: now, every logical statement can be encoded as a number. Every proof in the logic can be encoded as a sequence of numbers: if something is provable in the Principia logic, we can encode that proof as a string of numbers, and check the proof for correctness using nothing but (a whole heck of a lot of) arithmetic!
Next post, we'll finally get to the most important part of what Gödel did. We've been able to define what it means for a statement to be provable - we'll use that to show that there's a way of creating a number encoding the statement that something is not provable. And we'll show how that means that there is a true statement in the Principia's logic which isn't provable using the Principia's logic, which means that the logic isn't complete.
In fact, the proof that we'll do shows a bit more than that. It doesn't just show that the Principia's logic is incomplete. It shows that any consistent formal system like the Principia, any system which is powerful enough to encode Peano arithmetic, must be incomplete.
The first step in Gödel’s incompleteness proof was finding a way of taking logical statements and encoding them numerically. Looking at this today, it seems sort-of obvious. I mean, I’m writing this stuff down in a text file – that text file is a stream of numbers, and it’s trivial to convert that stream of numbers into a single number. But when Gödel was doing it, it wasn’t so obvious. So he created a really clever mechanism for numerical encoding. The advantage of Gödel’s encoding is that it makes it much easier to express properties of the encoded statements arithmetically. (Arithmetically means something very specific here; we’ll see what in a later post.
Before we can look at how Gödel encoded his logic into numbers, we need to look at the logic that he used. Gödel worked with the specific logic variant used by the Principia Mathematica. The Principia logic is minimal and a bit cryptic, but it was built for a specific purpose: to have a minimal syntax, and a complete but minimal set of axioms.
The whole idea of the Principia logic is to be purely syntactic. The logic is expected to have a valid model, but you shouldn’t need to know anything about the model to use the logic. Russell and Whitehead were deliberately building a pure logic where you didn’t need to know what anything meant to use it. I’d really like to use Gödel’s exact syntax – I think it’s an interestingly different way of writing logic – but I’m working from a translation, and the translator updated the syntax. I’m afraid that switching between the older Gödel syntax, and the more modern syntax from the translation would just lead to errors and confusion. So I’m going to stick with the translation’s modernization of the syntax.
The basic building blocks of the logic are variables. Already this is a bit different from what you’re probably used to in a logic. When we think of logic, we usually consider predicates to be a fundamental thing. In this logic, they’re not. A predicate is just a shorthand for a set, and a set is represented by a variable.
Variables are stratified. Again, it helps to remember where Russell and Whitehead were coming from when they were writing the Principia. One of their basic motivations was avoiding self-referential statements like Russell’s paradox. In order to prevent that, they thought that they could create a stratified logic, where on each level, you could only reason about objects from the level below. A first-order predicate would be a second-level object could only reason about first level objects. A second-order predicate would be a third-level object which could reason about second-level objects. No predicate could ever reason about itself or anything on its on level. This leveling property is a fundamental property built into their logic. The way the levels work is:
Type one variables, which range over simple atomic values, like specific single natural numbers. Type-1 variables are written as , .
Type two variables, which range over sets of atomic values, like sets of natural numbers. A predicate, like IsOdd, about specific natural numbers would be represented as a type-2 variable. Type-2 variables are written , , …
Type three variables range over sets of sets of atomic values. The mappings of a function could be represented as type-3 variables: in set theoretic terms, a function is set of ordered pairs. Ordered pairs, in turn, can be represented as sets of sets – for example, the ordered pair (1, 4) would be represented by the set { {1}, {1, 4} }. A function, in turn, would be represented by a type-4 variable – a set of ordered pairs, which is a set of sets of sets of values.
Using variables, we can form simple atomic expressions, which in Gödel’s terminology are called signs. As with variables, the signs are divided into stratified levels:
Type-1 signs are variables, and successor expressions. Successor expressions are just Peano numbers written with “succ”: 0, succ(0), succ(succ(0)), succ(a1), etc.
Signs of any type greater than 1 are just variables of that type/level.
Once you have signs, you can assemble the basic signs into formulae. Gödel explained how to build formulae in a classic logicians form, which I think is hard to follow, so I’ve converted it into a grammar:
elementary_formula → signn+1(signn)
formula → ¬(elementary_formula)
formula → (elementary_formula) or (elementary_formula)
formula → ∀ signn (elementary_formula)
That’s the entire logic! It’s tiny, but it’s enough. Everything else from predicate logic can be defined in terms of combinations of these basic formulae. For example, you can define logical “and” in terms of negation and logical “or”: (a ∧ b) ⇔ ¬ (¬ a ∨ ¬ b).
With the syntax of the system set, the next thing we need is the basic axioms of logical inference in the system. In terms of logic the way I think of it, these axioms include both “true” axioms, and the inference rules defining how the logic works. There are five families of axioms.
First, there’s the Peano axioms, which define the natural numbers.
: 0 is a natural number, and it’s not the successor of anything.
: Successors are unique.
: induction works on the natural numbers.
Next, we’ve got a set of basic inference rules about simple propositions. These are defined as axiom schemata, which can be instantiated for any set of formalae , , and .
Axioms that define inference over quantification. is a variable, is any formula, is any formula where is not a free variable, and is a sign of the same level as , and which doesn’t have any free variables that would be bound if it were inserted as a replacement for .
: if formula is true for all values of , then you can substitute any specific value for in , and must still be true.
The Principia’s version of the set theory axiom of comprehension:
And last but not least, an axiom defining set equivalence:
So, now, finally, we can get to the numbering. This is quite clever. We’re going to use the simplest encoding: for every possible string of symbols in the logic, we’re going to define a representation as a number. So in this representation, we are not going to get the property that every natural number is a valid formula: lots of natural numbers won’t be. They’ll be strings of nonsense symbols. (If we wanted to, we could make every number be a valid formula, by using a parse-tree based numbering, but it’s much easier to just let the numbers be strings of symbols, and then define a predicate over the numbers to identify the ones that are valid formulae.)
We start off by assigning numbers to the constant symbols:
Symbols
Numeric Representation
0
1
succ
3
¬
5
∨
7
∀
9
(
11
)
13
Variables will be represented by powers of prime numbers, for prime numbers greater that 13. For a prime number p, p will represent a type one variable, p2 will represent a type two variable, p3 will represent a type-3 variable, etc.
Using those symbol encodings, we can take a formula written as symbols x1x2x3…xn, and encode it numerically as the product 2x13x25x2…pnxn, where pn is the nth prime number.
For example, suppose I wanted to encode the formula: ∀ x1 (y2(x1)) ∨ x2(x1).
First, I’d need to encode each symbol:
“∀” would be 9.
“x1“” = 17
“(” = 11
“y2” = 192 = 361
“(” = 11
“x1” = 17
“)” = 13
“∨” = 7
“x2” = 172 = 289
“(” = 11
“x1” = 17
“)” = 13
“)” = 13
The formula would thus be turned into the sequence: [9, 17, 11, 361, 11, 17, 13, 7, 289, 11, 17, 13, 13]. That sequence would then get turned into a single number 29 317 511 7361 1111 1317 1713 197 23289 2911 3117 3713 4113, which according to Hugs is the number (warning: you need to scroll to see it. a lot!):
Next, we’re going to look at how you can express interesting mathematical properties in terms of numbers. Gödel used a property called primitive recursion as an example, so we’ll walk through a definition of primitive recursion, and show how Gödel expressed primitive recursion numerically.
I’m going to be on vacation this week, which means that I won’t have time to write new posts. But my friend Dr. SkySkull was just talking about Gödel on twitter, and chatting with him, I realized that this would be a good time to repost some stuff that I wrote about Gödel’s incompleteness proof.
Incompleteness is one of the most beautiful and profound proofs that I’ve ever seen. If you’re at all interested in mathematics, it’s something that’s worth taking the effort to understand. But it’s also pretty on-topic for what I’ve been writing about. The original incompleteness proof is written for a dialect of math based on ST type theory!
It takes a fair bit of effort to work through the incompleteness proof, so it’ll be a weeks worth of reposts. What I’m going to do is work with this translation of the original paper where Gödel published his first incompleteness proof. Before we can get to the actual proof, we need to learn a bit about the particular kind of logic that he used in his proof.
It goes right back to the roots of type theory. Set theory was on the rocks, due to Russell’s paradox. Russell’s paradox did was show that there was a foundational problem in math. You could develop what appeared to be a valid mathematicial structure and theory, only to later discover that all the work you did was garbage, because there was some non-obvious fundamental inconsistency in how you defined it. But the way that foundations were treated simple wasn’t strong or formal enough to be able to detect, right up front, whether you’d hard-wired an inconsistency into your theory. So foundations had to change, to prevent another incident like the disaster of early set theory.
In the middle of this, along came two mathematicians, Russell and Whitehead, who wanted to solve the problem once and for all. They created an amazing piece of work called the Principia Mathematica. The principia was supposed to be an ideal, perfect mathematical foundation. It was designed to have to key properties: it was supposed to consistent, and it was supposed to be complete.
Consistent meant that the statement would not allow any inconsistencies of any kind. If you used the logic and the foundantions of the Principia, you couldn’t even say anything like Russell’s paradox: you couldn’t even write it as a valid statement.
Complete meant that every true statement was provably true, every false statement was provably false, and every statement was either true or false.
A big part of how it did this was by creating a very strict stratification of logic – the stratification that we discussed in ST type theory. The principia’s type-theoretic logic could reason about a specific number, using level-0 statements. You could reason about sets of numbers using level-1 statements. And you could reason about sets of sets of numbers using level-2 statements. In a level-1 statement, you could make meta-statements about level-0 properties, but you couldn’t reason about level-1. In level-2, you could reason about level-1 and level-0, but not about level-2. This meant that you couldn’t make a set like the set of all sets that don’t contain themselves – because that set is formed using a predicate – and when you’re forming a set like “the set of all sets that don’t contain themselves”, the sets you can reason about are a level below you. You can form a level-1 set using a level-1 statement about level-0 objects. But you can’t make a level-1 statement about level-1 objects! So self-referential systems would be completely impossible in the Principia’s logic. You just can’t even state Russell’s paradox. It’s inexpressible.
As a modern student of math, it’s hard to understand what a profound thing they were trying to do. We’ve grown up learning math long after incompleteness became a well-known fact of life. (I read “Gödel Escher Bach” when I was a college freshman – well before I took any particularly deep math classes – so I knew about incompleteness before I knew enough to really understand what completeness woud have meant!) The principia would have been the perfection of math, a final ultimate perfect system. There would have been nothing that we couldn’t prove, nothing in math that we couldn’t know!
What Gödel did was show that using the Principia’s own system, and it’s own syntax, that not only was the principia itself flawed, but that any possible effort like the principia would inevitably be flawed!
With the incompleteness proof, Gödel showed that even in the Principia, even with all of the effort that it made to strictly separate the levels of reasoning, that he could form self-referential statements, and that those self-referential statements were both true and unprovable.
The way that he did it was simply brilliant. The proof was a sequence of steps.
He showed that using Peano arithmetic – that is, the basic definition of natural numbers and natural number arithmetic – that you could take any principia-logic statement, and uniquely encode it as a number – so that every logical statement was a number, and ever number was a specific logical statement.
Then using that basic mechanic, he showed how you could take any property defined by a predicate in the principia’s logic, and encode it as a arithmetic property of the numbers. So a number encoded a statement, and the property of a number could be encoded arithmetically. A number, then, could be both a statement, and a definition of an arithmetic property of a stament, and a logical description of a logical property of a statement – all at once!
Using that encoding, then – which can be formed for any logic that can express Peano arithmetic – he showed that you could form a self-referential statement: a number that was a statement about numbers including the number that was statement itself. And more, it could encode a meta-property of the statement in a way that was both true, and also unprovable: he showed how to create a logical property “There is no proof of this statement”, which applied to its own numeric encoding. So the statement said, about itself, that it couldn’t be proven.
The existence of that statement meant that the Principia – and any similar system! – was incomplete. Completeness means that every true statement is provably true within the system. But the statement encodes the fact that it cannot be proven. If you could prove it, the system would be inconsistent. If you can’t, it’s consistent, but incomplete.
Most programmers are familiar with λ-calculus. It’s one of the most widely used tools in theoretical computer science and logic. It’s the basis of many programming languages, including Lisp, Haskell, ML, and Scala. It’s had a strong influence on many other programming languages that aren’t strictly based on it, including Java, C++, and Javascript.
Motivation: the Problem
Modern programmers love the λ-calculus. A lot of the mathematicians who worked in what became computer science also loved it. But if you go back to its roots, there was a problem.
The λ-calculus in its non-typed form, as it was originally defined, was inconsistent.
Haskell Curry eventually reduced the paradox to something quite simple:
That is a function which returns if is true.
To see the paradox, we need to change how we think of λ-calculus. Most people today who know λ-calculus are programmers, and we think of it primarily as something like a programming language. But the roots of λ-calculus were laid before computers as we know them existed. At the time, λ-calculus was a tool used by logicians. To them it wasn’t a computing machine, it was a logical model of computation.
When we look at the expression , what we see is executable logic that reads as “If applying to returns true, then return y”. And by using computational reasoning, we’d conclude that is a non-terminating computation, because to get the value of , we need to evaluate , and then apply to that result. But to logicians like Haskell Curry, it read is “The statement implies y”. Rendered into simple english, it’s a statement like: “If this statement is true, then my hair is purple”. It’s purely a logical implication, and so even though we can’t actually evaluate , in logical terms, we can still say “This is a well-formed logical statement, so is it true?”.
Is that true? Suppose it is. If it’s true, then that means that it says that whatever is must be true. Without knowing what is, we can’t be sure if this is a true statement.
Suppose that it’s false. If is false, that means that the implication must be true, because FOPL says that if the antecedent of an implication is false, the entire implication is true.
It’s clearer when you look at the english: If this sentence is true, then my hair is purple”. My hair isn’t purple, which means that the statement can’t be true. But if the statement isn’t true, then the implication is true, so the statement is true. We’re caught in a self-reference loop, just like what we saw in Russell’s paradox.
This was considered a very bad thing. It’s a bit subtler than the problem with naive set theory. In set theory, we had an unambiguous inconsistency: we had a set that was well-defined under the axioms of set theory, and without any question, that set was inconsistent. Here, we’ve got an expression which might be consistent, and then again, it might not. It depends on what the consequent – the “my hair is purple” part – of the implication is. If it’s something true, then we’re fine. If it’s not, then we’re stuck.
The problem is, no matter what you put into that “my hair is purple” part, you can use this to produce a proof that it’s true, even if it isn’t. And that’s a fundamental inconsistency, which can’t be tolerated.
Curry’s paradox meant that the logicians working with λ-calculus had a problem that they needed to solve. And following the fashion of the time, they solved it using types. Much like ST type theory attempted to preserve as much of set theory as possible while fixing the inconsistency, typed λ-calculus tried to fix the inconsistency of λ-calculus. The basic approach was also similar: the typed λ-calculus introduced a stratification which made it impossible to build the structures that led to inconsistency.
In ST, the solution was to build a logical system in which it was impossible to express self-reference. In λ-calculus, the basic goal was the same: to eliminate self-reference. But in λ-calculus, that restriction is stated differently. What the type system in λ-calculus does is make it impossible to construct a statement that is a fixed-point combinator.
If we look carefully at the paradoxical statement up above, it’s not really pure λ-calculus. It relies on the fact that we’re defining a function named r, and then applying r to itself using the name . But that’s just syntactic sugar: in fact, can’t reference . You need some tool to let you apply an expression to itself: that tool is called a fixed-point combinator. The most common fixed-point in λ-calculus is the Y combinator, which underlies how recursive computations usually work in λ-calculus.
The way that the simply typed λ-calculuss gets around the Curry paradox is by making it impossible to build a well-typed fixed-point combinator. Without that, you can’t build the self-referential constructs that cause the inconsistency. The downside is that the simply typed λ-calculus, without a fixed point combinator, is not Turing complete. The evaluation of every simple typed λ-calculus expression will eventually terminate.
(As an aside: this isn’t really a problem in practice. The self-referential expressions that cause the Curry paradox turn into non-terminating computations. So they don’t produce a paradox; they just don’t produce anything. Logical inconsistencies don’t produce results: they’re still an error, instead of terminating with an inconsistent result, they just never terminate. Again, to the logicians at the time, the idea of non-termination was, itself, a deep problem that needed a solution.)
The Solution: Stratification by Types
The way that the simply typed λ-calculus fixed things was by creating a stratification using types. The type system created a restriction on the set of statements that were valid, well-formed logical statements. That restriction made it impossible to express a fixed point combinator or a general recursive computation of any kind.
It’s helpful to once again refer back to ST. In ST, we started the type of atoms at level 0. To get to level 1, we defined predicates over level-0 objects, and the set of objects that matched the predicate was a level-1 type. Then we could define predicates over level-1 objects, and the set of level-1 types that satisfied the predicate was a level-2 type, and so on. In the simply typed λ-calculus, we do the same thing, but with functions: we can build functions that operate on primitive atoms (also called base values), or on other functions. When we define a function, it must be assigned a type, and that type must be something at a lower level than the function being defined. You can’t ever pass a function to itself, because the function is an object at a higher level than the type of its parameter.
We start with base types. Every simply-typed lambda calculus starts with a collection of primitive atomic values. The set of atomic values is partitioned into a collection of types, which are called the base types. Base types are usually named by single lower-case greek letters: So, for example, we could have a type which consists of the set of natural numbers; a type which corresponds to boolean true/false values; and a type which corresponds to strings.
Once we have basic types, then we can talk about the type of a function. A function maps from a value of one type (the type of parameter) to a value of a second type (the type of the return value). For a function that takes a parameter of type , and returns a value of type , we write its type as ““. The “” is called the function type constructor; it associates to the right, so is equivalent to .
In every function declaration, we need to specify the type of the parameters and the type of the result. So:
is a function which takes natural number as a parameter, and returns a natural number as a result.
is a function which takes a function as a parameter, and produces a natural number as a result.
As usual in λ-calculus, we don’t have multi-parameter functions – all functions are curried, so a function like addNatural would be a function that takes a natural number as a paramater, and returns a function that takes a natural number and returns a natural number. So the type of addNatural is .
How does this get around the self-reference problem? A function like the one in the Curry paradox takes an object of its own type as a parameter. There’s no way to write that in a type system. It’s a significant restriction which makes it impossible to write general recursive expressions – it limits us to something close to primitive recursion, but it avoids the inconsistency. All valid expressions written with this system of types in place is guaranteed to terminate with a consistent result.
Extending λ-calculus with types
Now, it’s time to get at least a little bit formal, to see how we integrate a stratified type system into the lambda calculus. There’s two facets to that: the syntactic, and the analytic. The syntactic part shows how we extend λ-calculus to include type declarations, and the analytic part shows how to determine whether or not an expression with type declarations is valid.
The syntax part is easy. We add a “:” to the notation; the colon has an expression or variable binding on its left, and a type specification on its right. It asserts that whatever is on the left side of the colon has the type specified on the right side. A few examples:
This asserts that the parameter, has type , which we’ll use as the type name for the natural numbers. (In case it’s hard to tell, that’s a greek letter “nu” for natural.) There is no assertion of the type of the result of the function; but since we know that “+” is a function with type , we can infer that the result type of this function will be .
This is the same as the previous, but with the type declaration moved out, so that it asserts the type for the lambda expression as a whole. This time we can infer that because the function type is , which means that the function parameter has type .
This is a two parameter function; the first parameter has type ν, and the second has type δ. We can infer the return type, which is ν. So the type of the full function is ν → δ → ν. This may seem surprising at first; but remember that λ-calculus really works in terms of single parameter functions; multi-parameter functions are a shorthand for currying. So really, this function is: λ x : ν . (λ y : δ . if y then x * x else x); the inner lambda is type δ → ν; the outer lambda is type ν → (δ → ν).
To talk about whether a program is valid with respect to types (aka well-typed), we need to introduce a set of rules for checking the validity of the type declarations. Using those rules, we can verify that the program is type-consistent.
In type analysis, we’ll talk about judgements. When we can infer the type of an expression using an inference rule, we call that inference a type judgement. Type analysis allows us to use inference and judgements to reason about types in a lambda expression. If any part of an expression winds up with an inconsistent type judgement, then the expression is invalid. If we can show that all of the components of an expression have consistent type judgements, then we can conclude that the expression is well-typed, meaning that it’s valid with respect to the type system.
Type judgements are usually written in a sequent-based notation, which looks like a fraction where the numerator consists of statements that we know to be true; and the denominator is what we can infer from the numerator. In the numerator, we normally have statements using a context, which is a set of type judgements that we already know;it’s usually written as an uppercase greek letter. If a type context includes the judgement that , I’ll write that as .
Rule 1: Type Identity
This is the simplest rule: if we have no other information except a declaration of the type of a variable, then we know that that variable has the type it was declared with.
Rule 2: Type Invariance
This rule is a statement of non-interference. If we know that , then inferring a type judgement about any other term cannot change our type judgement for .
Rule 3: Function Type Inference
This statement allows us to infer function types given parameter types. Ff we know the type of the parameter to a function is ; and if, with our knowledge of the parameter type, we know that the type of term that makes up the body of the function is , then we know that the type of the function is .
Rule 4: Function Application Inference
This one is easy: if we know that we have a function that takes a parameter of type and returns a value of type , then if we apply that function to a value of type , we’ll get a value of type .
These four rules are it. If we can take a lambda expression, and come up with a consistent set of type judgements for every term in the expression, then the expression is well-typed. If not, then the expression is invalid.
So let’s try taking a look at a simple λ-calculus expression, and seeing how inference works on it.
Without any type declarations or parameters, we don’t know the exact type. But we do know that “x” has some type; we’ll call that “α”; and we know that “y” is a function that will be applied with “x” as a parameter, so it’s got parameter type α, but its result type is unknown. So using type variables, we can say “x:α,y:α→β”. We can figure out what “α” and “β” are by looking at a complete expression. So, let’s work out the typing of it with x=”3″, and y=”λ a:ν.a*a”. We’ll assume that our type context already includes “*” as a function of type “ν→ν→ν”, where ν is the type of natural numbers.
“λ x y . y x) 3 (λ a:ν . a * a)”: Since 3 is a literal integer, we know its type: 3:ν.
By rule 4, we can infer that the type of the expression “a*a” where “a:ν” is “ν”, and *:ν→ν→ν so therefore, by rule 3 the lambda expression has type “ν→ν”. So with type labelling, our expression is now: “(λ x y . y x) (3:ν) (λ a:ν.(a*a):ν) : ν→ν”.
So – now, we know that the parameter “x” of the first lambda must be “ν”; and “y” must be “ν→ν”; so by rule 4, we know that the type of the application expression “y x” must be “ν”; and then by rule 3, the lambda has type: “ν→(ν→ν)→ν”.
So, for this one, both α and β end up being “ν”, the type of natural numbers.
So, now we have a simply typed λ-calculus. The reason that it’s simply typed is because the type treatment here is minimal: the only way of building new types is through the unavoidable constructor. Other typed lambda calculi include the ability to define parametric types, which are types expressed as functions ranging over types.
Programs are Proofs
Now we can get to the fun part. The mantra of type theory is the program is the proof. Here’s where we get our first glimpse of just what that really means!
Think about the types in the simple typed language calculus. Anything which can be formed from the following grammar is a λ-calculus type:
type ::= primitive | function | ( type )
primitive ::= α | β | δ | …
function ::= type→type
The catch with that grammar is that you can create type expressions which, while they are valid type definitions, you can’t write a single, complete, closed expression which will actually have that type. (A closed expression is one with no free variables.) When there is an expression that has a type, we say that the expression inhabits the type; and that the type is an inhabited type. If there is no expression that can inhabit a type, we say it’s uninhabitable. Any expression which either can’t be typed using the inference rules, or which is typed to an uninhabitable type is a type error.
So what’s the difference between inhabitable type, and an uninhabitable type?
The answer comes from something called the Curry-Howard isomorphism. For a typed λ-calculus, there is a corresponding intuitionistic logic. A type expression is inhabitable if and only if the type is a provable theorem in the corresponding logic.
The type inference rules in λ-calculus are, in fact, the same as logical inference rules in intuitionistic logic. A type can be seen both as a statement that this is a function that maps from a value of type to a value of type , and as a logical statement that if we’re given a fact , we could use that to infer the truth of a fact .
If there’s a logical inference chain from an axiom (a given type assignment) to an inferred statement, then the inferred statement is an inhabitable type. If we have a type , then given a inhabited type , we know that is inhabitable, because if is a fact, then is also a fact.
On the other hand, think of a different case . That’s not a theorem, unless there’s some other context that proves it. As a function type, that’s the type of a function which, without including any context of any kind, can take a parameter of type α, and return a value of a different type β. You can’t do that – there’s got to be some context which provides a value of type β – and to access the context, there’s got to be something to allow the function to access its context: a free variable. Same thing in the logic and the λ-calculus: you need some kind of context to establish “α→β” as a theorem (in the logic) or as an inhabitable type (in the λ-calculus).
What kind of context would make a type inhabitable? A definition of a valid function that takes an α, and returns a β. If such a function exists, then that function is a proof of the inhabitility of the type. Literally, the program is the proof.
This post started off as an introduction to a post about the simply typed lambda calculus. It got a bit out of control – but reading it over, I think that it’s valuable background. So I’ve made it into its own post.
ST type theory is an interesting idea, but it’s mostly interesting as a historical curiosity and background. Type theory started with things like ST, but it turned into something very different. You can see the roots in ST, but modern type theory takes a completely different approach. ST is an axiomatic foundation for a stratified version of type theory. Modern type theory, in contrast, has constructed a universe of mathematics that, rather than being based on an axiomatic foundation of first order predicate logic, is based almost entirely on ideas of computability and computation.
The core of the modern version of type theory is the intuitionistic type theory of Per Martin-Lof, and it’s part of the constructionist school of math.
Like ST type theory, constructivism can also been seen as a reaction to paradox and inconsistency. Some mathematicians decided that the right way to approach the problem of paradox was to build a better, stronger axiomatic foundation. That effort let to things like ST type theory, ZFG/NBG set theory, and the principia mathematica. But others thought that that approach was wrong.
The axiomatic approach ends up with things like the axiom of choice in its foundation. And the axiom of choice leads directly to results that seem to be completely nonsensical. For example, the classic Banach-Tarski paradox.. Banach-Tarski says that there’s a way of taking a sphere the size of an orange, cutting it into some very odd slices, and then reassembling those slices into two oranges exactly the same size as the original. On the face of it, that’s ridiculous!
The key to Banach-Tarski is that it’s built on an operation that’s impossible in reality. It’s exploiting the boundaries of a theory. You start with a sphere. That’s an object on which metrics like “volume” are well-defined. You’re “cutting” it – not really cutting, but actually subdividing it – into pieces. Those pieces are objects where the metrics no longer work. You’ve broken the metric. And then, you’ve got objects for which the entire concept of volume no longer makes any sense, and you reassemble them into new objects – and those new objects are, once again, objects where the volume metric works.
From one point of view, you’ve done something that makes sense. You started with a topological space with meaningful metrics. A topological space is just a set with a bunch of cute structural properties – the neighborhood relationships. Those structural properties in turn have higher order structure properties, which can be used to define metrics like distance and volume. So the original sphere has a meaningful volume. But still, mathematically, it’s just a set with neighborhood relationships.
Since it’s just a topological space, you can divide it into sub-spaces – that is, subsets which retain structural properties. They’re still topological spaces, but now, the neighborhood relations, because of the way that you divided the original set, no longer have the properties that you need to define metrics. They’re not metric spaces.
When you recombine them, you can combine them into two new topological spaces that do have the properties that you need to define metrics – so volumes are, once again, meaningful. But in that process, you’re redefining the metrics, and so they can be redefined in any way that you want, producing any results that you want.
There’s a pretty strong argument that that entire process is an abuse of the underlying axioms. It only works because you can destroy the metric, and then recreate it. When you state what’s going on clearly, it seems like it’s cheating. But according to the standard axiomatic set-theory based math, everything that happens is completely legal. It’s ridiculous and non-sensical, and it produces a result that looks like it must be obviously wrong, but according to the axioms, it’s just fine.
The problem of cheating on the metrics is bad, but it’s not all that’s wrong with Banach-Tarski according to the constructivists. B-T says that you can cut a spherical metric space into pieces. Only you really can’t – it’s all just a clever sleight-of-hand! You can’t describe or specify how to cut the original sphere into pieces. There is no shape, no structure, no process that you can use to actually cut the sphere. The axioms say that such a cut exists, but the actual method of cutting is not just unknown, but essentially unknowable.
The constructivists argue that that’s rubbish. How can you argue that it exists, but we can’t produce it, we can’t find it, we can’t study it. According to the constructivists, it exists only as an artifact of a flawed system. It’s meaningless to say that something exists if it only exists in an unreachable theoretical ether.
The constructivists say that things like Banach-Tarski and the Russell paradox are part of the same basic problem: defining things not by how they can be created, but by how they can be described using some fuzzy airy-fairy gibberish derived from axioms. The solution isn’t to find a better set of axioms, but to find a fundamentally different way of doing things.
The constructivist method says that the way to do math is to build things. That the only way you can really consider a statement to be true is if you have concrete proof: the only way to prove that something exists is to show a concrete example of it. The only way to prove that something is false is with a specific counterexample.
That leads to an absolutely fascinatingly different way of doing math, which is what we’ll see in Martin-Lof’s intuitionistic type theory. When you talk about typed programming languages, you’ll hear a mantra: “The program is the proof”. That is literally true. In Martin-Lof’s intuitionistic type theory, the way that you prove things is by, essentially, writing programs! A proof of a fact is a computation. A proof of an existential statement isn’t just some abstract reasoning that shows that it exists – it’s a computation that produces a concrete example. A proof of a universal statement is a metaproof – a program that, given any value, produces a proof specific to that value.
It avoids the basic problem with the axiomatic problem. You can’t have something ridiculous like the set of all sets that don’t include themselves, because the only way to show that a set exists is to show a process to create it – and there’s no way to create a paradoxical set! You don’t get nonsense like Banch-Tarski, because the division of the spherical topological space into the non-metric subspaces is impossible: you can’t show a process that produces it. In the world of intuitionism and constructivism, existence proofs that don’t produce concrete examples don’t exist!
It’s an impressive thing, and it’s really a mind-blowingly different way of understanding what it is to do mathematics.
For introducing Martin-Lof’s type theory, I’m going to be mostly working from the Nordstrom/Petersson/Smith text, with supplementation from many different sources. For the programming language oriented part, I highly recommend Types and Programming Languages by Benjamin Pierce.
Before we really get started, I’m going to back and do some review. I’m going to go start with an introduction to the simply typed lambda calculus, and intuitionistic logic, because they’re both really essentials for understanding what’s coming next. So that will be the next couple of posts.
I’ve been writing this blog for a long time. It’s pretty amazing to me to realize just how long – the original version of Good Math/Bad Math started over 9 years ago! I’ve gone through some times when the blog was really busy, and some when it was really slow. Lately, it’s been the latter. Since my mom died a few months back, I’ve been depressed, and finding enough motivation to blog after a full day of work has been difficult. But I’m trying to get back to normal, and start updating the blog at least a couple of times a week.
A few weeks back, one of my blog-friends asked me to write about type theory. Type theory comes up a lot in programming language design, particularly in the functional programming world. If you can’t talk intelligently about quantified types, existential types, dependent types, and similar stuff, you’re largely locked out of discussions.
I’ve taken a couple of weak stabs at type theory over the years, but I’ve never tried to really do it justice. It’s a hard topic, and even though it’s got a lot of overlap with my professional focus, I’ve never been formally trained in it. I’ve never actually taken a course in type theory – I’ve learned it on my own, as I’ve studied programming languages and denotational semantics.
Now seems like a good time to give it a try. It’s a subject that I’m obviously pretty interested in.
To start, I’m going to recycle a couple of old posts. I’ve written about the simplest version of type theory that I know, something called ST. I’m rewriting tha old post here. After that, I’ll rewrite some material about the simply typed lambda calculus, putting into a more type-theoretic framework. Then I’ll move from there into basic type theory, intuitionistic type theory, and the various type system heirarchies, like System-T, System-F, Lambda-cube, etc.
So, today: ST type theory.
I’ve said many times that I’m a programming language guy, and that’s how I approach this stuff. For someone who works on programming languages, types are old hat. They seem like such an obvious idea that it’s hard to conceive of a world in which they aren’t a part of the mathematical background. But in the world of math, they’re a relatively recent invention. (In computer science, they’re ancient history: type theory predates the first real computers.)
The roots of type theory are the same as the roots of axiomatic set theory. The point wasn’t to support anything computational; the point was to try to salvage set theory. Cantor had devised set theory, and once people started to understand it, the mathematical community thought it was the neatest thing ever! Set theory was just wonderful! Except for the part where it was a total inconsistent train wreck.
Mathematicians love set theory. It’s a system on which all of mathematics can be built, using a basis which is simple, using nothing but intuitively clear concepts. That’s lovely. Unfortunately, as we know, simple intuitive ideas often don’t work. Cantor’s set theory had a huge problem: it was inconsistent.
Here’s the problem.
In set theory, you’ve got these collection of things called sets. The main thing that you can do with sets is say, “I’ve got this object here. You’ve got a set. Is my object part of your set?”. For any possible pair of object and set, there can be only one correct answer: either the object is in the set, or it isn’t. There’s no middle ground: there’s no way an can be both in and not in a set.
In Cantor’s version of set theory, you could define a set using logic, in a process called comprehension. He said that if you can write a logical predicate, then there’s a set which contains the collection of objects that satisfy that predicate. Using comprehension, you can define sets that range over sets. For example, you can define the set of all sets with an even number of elements.
The catch is that Cantor didn’t place any restrictions on those predicates. So you can create sets based on predicates that range over themselves. You can define a set which is a member of itself, like the set of all sets.
Using that, you can make up some silly sets. For example: Is the set of all sets that contain themselves a member of itself?
Well, if it is, then it is. If it isn’t, then it isn’t. Both yes and no! The english statement, “the set of all sets that contain themselves”, doesn’t uniquely identify one set. There are two different sets that match that description! There’s one that does contain itself, and there’s one that doesn’t!
We’ve already a problem in a lesser way: even written in careful predicate logic, the definition is ambiguous when it shouldn’t be. But there’s more trouble ahead. If we can define the set of all sets that do contain themselves as a member, then we can also define the set of all sets that do not contain themselves as a member.
Let – that is, it’s the set of all sets that do not contain themselves as a member. Is ?
If is not a member of itself, then by the definition in the comprehension, it must be a member of itself. But if it is a member of itself, then by that same definition, it can’t be. It can’t be a member of itself. But it also can’t not be a member of itself.
That’s a demonstration of the fundamental inconsistency in Cantor’s set theory, and it’s commonly known as Russell’s paradox. It’s caused by the ability to build unlimited self-referential statements about sets and set membership.
Inconsistency is a big deal in mathematics: if you’re working in an inconsistent system, then every statement is provably true in that system. That’s another way of saying that proving something in an inconsistent system is completely useless, because the proof doesn’t actually tell you that the thing you proved is true!
Using Cantor’s formulation of set theory, I can start with a statement that I know really is true, and I can work out a valid proof to show that it’s true. But I can also start with a statement that I know is false, and I can work out a perfectly valid proof that shows that false statement is true. I can prove that the sum of the integers from 1 to N is , and I can also prove that .
Any inconsistenty in a formal system means that the entire system is useless. Russell’s paradox meant that nothing that had been proven with set theory could be trusted! None of the methods of proof that people had come to love from working with set theory could be followed, because the entire basis was inconsistent!
Mathematicians wanted to find a way to preserve as much of set theory as possible, while getting rid of the inconsistency. That led to a lot of different systems. I’ve talked a lot on this blog about axiomatic set theory, which was the most well-known and widely accepted approach to the problem. Type theory is a different one.
What type theory does is start with a notion very similar to sets: collections of objects. The difference is that in type theory, instead of having sets which define collections of objects using logical predicates, in type theory, you have collections called types. The types are highly stratified, in a way that prevents you from creating anything self-referential.
The way that you do that is by building a ladder of types. Any type theory has some collection of primitive atoms. An atom is, as the name suggests, a simple object which isn’t made up of other objects. An atom is just itself – it doesn’t contain anything.
In our ladder of types, we start with the atoms. Atoms are level-0 objects. Using atoms, you can define types, which are collections of atoms. A level-1 type is defined by a predicate over level-0 objects. The level-1 type is, itself, a level-1 object. So a level-1 object is a collection of level-0 objects. A level-1 type can only range over level-0 objects, so it’s impossible for a level-1 object to contain itself. No self-reference paradox can even be written here!
You can continue the process by adding new levels. You can define level-1 predicates (that is, predicates ranging over level-1 types) – and the resulting collection is a level-2 type. And so on: any level-N type is a collection of types from level N-1, defined by a level N-1 predicate.
This produces a strict ladder of types and objects, and no type can contain anything from its own level. Russell’s paradox is averted. But the cost is complexity: most theorems that were provable in set theory are also provable in type theory, but they’re often a lot more complicated, both in how they’re stated, and in how they’re proven.
Of course, as I always say, informal explanations of formal things are always wrong. Formality exists for a reason: it allows us to say things in precise, unambiguous ways. If we want to understand even the simplest bits of type theory, we can’t just stop with the informal explanation: we need to hit the formalisms as well.
We’re going to start with the simplest version of type theory, a system called ST. ST is defined axiomatically. The axioms are, mostly, very similar to the basics of axiomatic set theory – especially to the NBG formulation. In NBG set theory, we have a collection of axioms that define what sets are and how they work. We define set equality with an axiom of extensionality; we define how we can construct new sets using logical predicate via an axiom of comprehension; we define the existence of infinite sets using an axiom of infinity. In ST type theory, we have similar axioms – identity/extensionality, comprehension, and infinity (but as we’ll see, the ST axiom of infinity is strange and back-handed compared to NBG).
The axioms explicitly capture the idea of stratification that I described informally above. In each axiom, I’ll refer to objects of one level using lowercase letters; I’ll write objects of the next higher level by appending a prime-mark to the letters. So if is a level-1 object, then would be a level-2 object.
ST has four axiom schemas.
Axiom of Identity:
This is straightforward – it’s an upside-down version of the axiom of extensionality in NBG set theory. If two objects are members of exactly the same collection of types, then they’re equal. Another way of saying that is that two objects are equal if there is no predicate that can distinguish between them.
Axiom of Extensionality:
This is pretty much an exact copy of the NBG axiom of extensionality, except that it specifies the fact that an object can only be in a type that is one level higher than .
Axiom of Comprehension: If is a th-order predicate, then
This is very similar to the axiom of comprehension from NBG set theory, modified for the strict stratification of type theory. It says that if there’s a predicate over level- objects, then the set of level- objects that satisfy that predicate are a level type.
Axiom of Infinity:
There exists a relation, “”, which ranges over pairs of atoms, and which is total, irreflexive, transitive, and strongly connected, such that .
This axiom is a strange beast. It’s defining the fact that there is an infinitely large type, but it’s doing it in a very backhanded way. In set theory, we were able to use Cantor numbers to define an infinite sequence of sets corresponding to natural numbers – and then using the construction of natural numbers with the other axioms, we could build more expansive sets of numbers – integers, reals, complex, etc.
But in type theory, we can’t do that. The Cantor numbers are defined by using things that belong not just to different types, but to different type strata. In cantor numbers, the number is the set of the representation for . So the cantor-0 is the empty-set, which is level-0. The Cantor-1 is the set containing the empty set, which is level 1. The Cantor 2 is the set containing the Cantor 1 – which is level 2. And so on. The canonical infinite set in axiomatic set theory is an object which can’t exist in type theory, because it’s got members that span multiple levels.
In ST type theory, there’s no simple constructive way of building an infinite collection like the Cantor numerals which doesn’t violate the stratification of type theory. So type theory needs to go at in a different way.
The way it does it is by defining a relation between atoms that can only be satisfied by an infinitely large set. The existence of the relation over the type implies that the type must also exist. The relation itself isn’t that hard – what’s hard about it is grasping the full implication of it. The relation is just something that behaves like numeric less-than:
It’s a relation over a pair of values. You can think of it as a function, .
It’s total, meaning that every possible value appears as both the left and the right parameter of <: so no matter what, for any value , there is some atom where , and some atom where .
It’s irreflexive: so there is no smallest number , where .
It’s transitive – so if and , then .
It’s strongly connected – so there isn’t a group of free-standing finite pools.
All of that, together, means that there’s an infinitely large pool of numbers, and that they’ve got enough properties to represent the integers.
ST type theory is, in my opinion, a mixed bag. From the perspective of a programming language guy, we haven’t gotten anything out of it that’s particularly valuable. It’s not particularly expressive. It is a simpler system, axiomatically, than type theory – and that’s nice. But proofs written using this kind of theory as a basis are more complicated – sometimes a lot more complicated – than they’d be in NBG or ZF set theory. The additional effort to understand the set theory axioms has a payoff in making everything easier.
But ST is just a starting point. In fact, most programming language type systems are derived from a very different school of type theory: Per Martin-Lof’s intuitionistic type theory. The basic ideas are similar, but intuitionistic type theory is much more useful in computer science.




and
, you can infer
if
is not free in
.
, if
.
. (For a bit of explanation, this rule means that we don’t need to have
rules –
can be treated as
, if
is not bound by instantiating
.
if
) \rightarrow ((\alpha \rightarrow \beta) \rightarrow (\alpha \rightarrow \gamma))")


)")


 \rightarrow ((\gamma \rightarrow \beta) \rightarrow (\alpha \lor \gamma) \rightarrow \beta)")




 \Rightarrow (r \lor p \Rightarrow r \lor q)")
](http://l.wordpress.com/latex.php?latex=%5Cforall%20v%28a%29%20%5CRightarrow%20%5Ctext%7Bsubst%7D%5Bv%2Fc%5D%28a%29&bg=FFFFFF&fg=000000&s=0 "\forall v(a) \Rightarrow \text{subst}[v/c](a)")
 \Rightarrow (b \lor \forall v(a))")
 ,
,  \Leftrightarrow a") . In our primitive recursive system, we can check if something is an instance of the reducibility axiom schema with:
. In our primitive recursive system, we can check if something is an instance of the reducibility axiom schema with: \Leftrightarrow y_2(y_1) \Rightarrow x_2 = x_1)") . Set equality is defined for all types of sets, so we need to have one version of axiom for each level. We do that using type-lifting: we say that the axiom is true for type-1 sets, and that any type-lift of the level-1 set axiom is also a version of the set axiom.
. Set equality is defined for all types of sets, so we need to have one version of axiom for each level. We do that using type-lifting: we say that the axiom is true for type-1 sets, and that any type-lift of the level-1 set axiom is also a version of the set axiom. ,
,  .
. ,
,  , …
, … = 0)") : 0 is a natural number, and it’s not the successor of anything.
: 0 is a natural number, and it’s not the successor of anything. = \text{succ}(y_1) \Rightarrow x_1 = y_1") : Successors are unique.
: Successors are unique. \land \forall x_1 (x_2(x_1) \Rightarrow x_2(succ(x_1)) \Leftrightarrow \forall x_1 (x_2(x_1))") : induction works on the natural numbers.
: induction works on the natural numbers. ,
,  , and
, and  .
.

 \rightarrow (p \lor r) \Rightarrow q \lor r")
 is a variable,
is a variable,  is any formula where
is any formula where  is a sign of the same level as
is a sign of the same level as ) \Rightarrow (b \lor \forall v(a))")
 \Rightarrow a))")
 \Rightarrow y_{i+1}(y_i)) \Rightarrow x_{i+1} = y_{i+1}")
 \Rightarrow y))")
 if
if ") is true.
is true. \Rightarrow y") , what we see is executable logic that reads as “If applying
, what we see is executable logic that reads as “If applying ") is a non-terminating computation, because to get the value of
is a non-terminating computation, because to get the value of  which consists of the set of natural numbers; a type
which consists of the set of natural numbers; a type  which corresponds to boolean true/false values; and a type
which corresponds to boolean true/false values; and a type  which corresponds to strings.
which corresponds to strings. , we write its type as “
, we write its type as “ “. The “
“. The “ ” is called the function type constructor; it associates to the right, so
” is called the function type constructor; it associates to the right, so  is equivalent to
is equivalent to ") .
. is a function which takes natural number as a parameter, and returns a natural number as a result.
is a function which takes natural number as a parameter, and returns a natural number as a result. \rightarrow \sigma") is a function which takes a
is a function which takes a  .
.
 , which we’ll use as the type name for the natural numbers. (In case it’s hard to tell, that’s a greek letter “nu” for natural.) There is no assertion of the type of the result of the function; but since we know that “+” is a function with type
, which we’ll use as the type name for the natural numbers. (In case it’s hard to tell, that’s a greek letter “nu” for natural.) There is no assertion of the type of the result of the function; but since we know that “+” is a function with type  , we can infer that the result type of this function will be
, we can infer that the result type of this function will be  .
.: \nu \rightarrow \nu")
 because the function type is
because the function type is  , which means that the function parameter has type
, which means that the function parameter has type 
 , I’ll write that as
, I’ll write that as  .
.

 , then inferring a type judgement about any other term cannot change our type judgement for
, then inferring a type judgement about any other term cannot change our type judgement for :\alpha \rightarrow \beta}")
: \beta}")

 , then given a inhabited type
, then given a inhabited type  – that is, it’s the set of all sets that do not contain themselves as a member. Is
– that is, it’s the set of all sets that do not contain themselves as a member. Is  ?
? is not a member of itself, then by the definition in the comprehension, it must be a member of itself. But if it is a member of itself, then by that same definition, it can’t be. It can’t be a member of itself. But it also can’t not be a member of itself.
is not a member of itself, then by the definition in the comprehension, it must be a member of itself. But if it is a member of itself, then by that same definition, it can’t be. It can’t be a member of itself. But it also can’t not be a member of itself.(n+1)}{2}") , and I can also prove that
, and I can also prove that  .
. 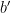 would be a level-2 object.
would be a level-2 object.

 that is one level higher than
that is one level higher than  is a
is a  th-order predicate, then
th-order predicate, then 
 type.
type.
 ”, which ranges over pairs of atoms, and which is total, irreflexive, transitive, and strongly connected, such that
”, which ranges over pairs of atoms, and which is total, irreflexive, transitive, and strongly connected, such that ") .
.
 \rightarrow \text{Boolean}") .
. appears as both the left and the right parameter of <: so no matter what, for any value
appears as both the left and the right parameter of <: so no matter what, for any value  , and some atom
, and some atom  where
where  .
. .
. , then
, then  .
.