
In my last post about category theory, I introduced the basic idea of typeclasses, and showed how to implement an algebraic monoid as a typeclass. Then we used that algebraic monoid as an example of how to think with arrows, and built it up into a sketch of category theory’s definition of a monoid. We ended with an ominous looking diagram that illustrated what a categorical monoid looks like.
In this post, we’re going to take a look at some of the formal definitions of the basic ideas of category theory. By the end of this lesson, you should be able to look at the categorical monoid, and understand what it means. But the focus of this post will be on understanding initial and terminal objects, and the role they play in defining abstractions in category theory. And in the next post, we’ll see how abstractions compose, which is where the value of category theory to programmers will really become apparrent.
Before I really get started: there’s a lot of terminology in category theory, and this post has a lot of definitions. Don’t worry: you don’t need to remember it all. You do need to understand the concepts behind it, but specifically remembering the difference between, say, and endomorphism, and epimorphism, and a monomorphism isn’t important: you can always look it up. (And I’ll put together a reference glossary to help make that easy.)
Defining Categories
A category is basically a directed graph – a bunch of dots connected by arrows, where the arrows have to satisfy a bunch of rules.
Formally, we can say that a category consists of a the parts: ")
is a collection of objects. We don’t actually care what the objects are – the only thing we can do in category theory is look at how the objects related through arrows that connect them. For a category
, we’ll often call this collection Obj(C).
is a collection of arrows, often called morphisms. Each element of
that goes from
to
, we’ll often write it as
. For a category
is a composition operator. For every pair of arrows
, there must be an arrow
called the compositions of
.
- To be a category, these must satisfy the following rules:
- Identity: For every object
, there must be an arrow from
to
. For any arrow
; and for any arrow
. That’s just a formal way of saying that composing an identity arrow with any other arrow results in the the other arrow.
- Associativity: For any set of arrows
.
- Identity: For every object
When talking about category theory, people often say that an arrow is a structure preserving mapping between objects. We’ll see what that means in slightly more detail with some examples.

A thing that I keep getting confused by involves ordering. Let’s look at a quick little diagram for a moment. The path from X to Z is 
)")
Example: The category Set
The most familiar example of a category (and one which is pretty canonical in category theory texts) is the category Set, where the objects are sets, the arrows between them are total functions, and the composition operator is function composition.
That might seem pretty simple, but there’s an interesting wrinkle to Set.
Suppose, for example, that we look at the function =x^2")

The answer is both – and many more. (It’s also a function from the reals to complex numbers, because every real number is also a complex number.) And so on. A function isn’t quite an arrow: an arrow is a categorical concept of some kind of mapping between two objects. In many ways, you can think of an arrow as something almost like a function with an associated type declaration: you can write many type declarations for a given function; any valid function with a type declaration that is an arrow in Set.
We’ll be looking at Set a lot. It’s a category where we have a lot of intuition, so using it as an example to demonstrate category concepts will be useful.
Example: The category Poset
Poset is the category of all partially ordered sets. The arrows between objects in posets are order-preserving functions between partially ordered sets. This category is an example of what we mean by structure-preserving mappings: the composition operator must preserve the ordering property.
For that to make sense, we need to remember what partially ordered set is, and what it means to be an order preserving function.
- A set
is partially ordered if it has a partial less-than-or-equal relation,
. This relation doesn’t need to be total – some values are less than or equal to other values; and some values can’t be compared.
- A function between two partially ordered sets
is order-preserving if and only if for all values
, if
in
, then
in
.
The key feature of an object in Poset is that is possesses a partial ordering. So arrows in the category must preserve that ordering: if 

")
")
That’s a typical example of what we mean by arrows as structure preserving: the objects of a category have some underlying structural property – and to be an arrow in the category, that structure must be preserved across arrows and arrow composition.
Commuting Diagrams
One of the main terms that you’ll hear about category diagrams is about whether or not the diagram commutes. This, in turn, is based on arrow chasing.
An arrow chase is a path through the diagram formed by chaining arrows together by composing them – an arrow chase is basically discovering an arrow from one object to another by looking at the composition of other arrows in the category.
We say that a diagram 
")

,: \circ(p_i) = \circ(p_j)")
For example: In this diagram, we can see two paths: 



Diagrams and Meta-level reasoning: an example
Let’s look at a pretty tricky example. We’ll take our time, because this is subtle, but it’s also pretty typical of how we do things in category theory. One of the key concepts of category theory is building a category, and then using the arrows in that category, create a new category that allows us to do meta-level reasoning.
We’ve seen that there’s a category of sets, called Set.
We can construct a category based on the arrows of Set, called Set→. In this category, each of the arrows in Set is an object. So, more formally, if ")
")
The arrows of this new category are where it gets tricky. Suppose we have two arrows in Set, 



")
")
The diagram is relatively easy to read and understand; explaining it in works is more complicated:
- an arrow in our category of Set-arrows is a mapping from one Set-arrow
- That mapping exists when there are two arrows
-
.
-
Another way of saying that is that there’s an arrow means that there’s a structure-preserving way of transforming any arrow from 

Why should we care about that? Well, for now, it’s just a way of demonstrating that a diagram can be a lot easier to read than a wall of text. But this kind of categorical mapping will become important later.
Categorizing Things
As I said earlier, category theory tends to have a lot of jargon. Everything we do in category theory involves reasoning about arrows, so there are many terms that describe arrows with particular properties. We’ll look at the most basic categories now, and we’ll encounter more in later lessons.
Monics, Epics, and Isos
The easiest way to think about all of these categories is by analogy with functions in traditional set-based mathematics. Functions and their properties are really important, so we define special kinds of functions with interesting categories. We have injections (functions from A to B where every element of A is mapped onto a unique element of B), surjections (functions from A to B where each element of B is mapped onto by an element of A), and isomorphisms.
In categories, we define similar categories: monomorphisms (monics), epimorphisms (epics), and isomorphisms (isos).
- An arrow
in category C is monic if for any pair of arrows
and
in C,
implies that
. (So a monic arrow discriminates arrows to its domain – every arrow to its domain from a given source will be mapped to a different codomain when left-composed with the monic.)
- An epic is almost the same, except that it discriminates with right-composition: An arrow
in category C is epic if for any pair of arrows
and
in C,
implies that
These definitions sound really confusing. But if you think back to sets, you can twist them into making sense. A monic arrow 


The same basic argument (reversed a bit) can show that an epic arrow is a surjective function in Set.
- An isomorphism is a pair of arrows
where
is epic, and where
, and
.
We say that the objects
Initial and Terminal Objects
Another kind of categorization that we look at is talking about special objects in the category. Categorical thinking is all about arrows – so even when we’re looking at special objects, what make them special are the arrows that they’re related to.
An initial object 0 in a category ")
")


")
For example, in the category Set, the empty set is an initial object, and singleton sets are terminal objects.
A brief interlude:
What’s the point?In this lesson, we’ve spent a lot of time on formalisms and definitions of abstract concepts: isos, monos, epics, terminals. And after this pause, we’re going to spend a bunch of time on building some complicated constructions using arrows. What’s the point of all of this? What does any of these mean?
Underlying all of these abstractions, category theory is really about thinking in arrows. It’s about building structures with arrows. Those arrows can represent import properties of the objects that they connect, but they do it in a way that allows us to understand them solely in terms of the ways that they connect, without knowing what the objects connected by the arrows actually do.
In practice, the objects that we connect by arrows are usually some kind of aggregate: sets, types, spaces, topologies; and the arrows represent some kind of mapping – a function, or a transformation of some kind. We’re reasoning about these aggregates by reasoning about how mappings between the aggregates behave.
But if the objects represent some abstract concept of collections or aggregates, and we’re trying to reason about them, sometimes we need to be able to reason about what’s inside of them. Thinking in arrows, the only way to really be able to reason about a concept like membership, the only way we can look inside the structure of an object, is by finding special arrows.
The point of the definitions we just looked at is to give us an arrow-based way of peering inside of the objects in a category. These tools give us the ability to create constructions that let us take the concept of something like membership in a set, and abstract it into an arrow-based structure.
Reasoning in arrows, a terminal object is an object in a category that captures a concept of a single object. It’s easiest to see this by thinking about sets as an example. What does it mean if an object, T, is terminal in the category of sets?
It means that for every set 


 = t")
By showing that there’s only one arrow from any object in the category of sets to T, we’re showing that can’t possibly have more than one object inside of it.
Knowing that, we can use the concept of a terminal object to create a category-theoretic generalization of the concept of set membership. If 



Constructions
We’re finally getting close to the real point of category theory. Category theory is built on a highly abstracted notion of functions – arrows – and then using those arrows for reasoning. But reasoning about individual arrows only gets you so far: things start becoming interesting when you start constructing things using arrows. In lesson one, we saw a glimpse of how you could construct a very generalized notion of monoid in categories – this is the first big step towards understanding that.
Products
Constructions are ways of building things in categories. In general, the way that we work with constructions is by defining some idea using a categorical structure – and then abstracting that into something called a universal construction. A universal construction defines a new category whose objects are instances of the categorical structure; and we can understand the universal construction best by looking at the terminal objects in the universal construction – which we can understand as being the atomic objects in its category.
When we’re working with sets, we know that there’s a set-product called the cartesian product. Given two sets, A and B, the product
 : a \in A, b \in B}.")
The basic concept of a product is really useful. We’ll eventually build up to something called a closed cartesian category that uses the categorical product, and which allows us to define the basis of lambda calculus in category theory.
As usual, we want to take the basic concept of a cartesian product, and capture it in terms of arrows. So let’s look back at what a cartesian product is, and see how we can turn that into arrow-based thinking.
The simple version is what we wrote above: given two sets A and B, the cartesian product maps them into a new set which consists of pairs of values in the old set. What does that mean in terms of arrows? We can start by just slightly restating the definition we gave above: For each unique value 

 \in A \times B")
But what do we actually mean by ")
It doesn’t matter which one we use: what matters is that there’s a key underlying property of the product: there are two functions and, called projection functions, which map elements of the product back to the elements of A and B. If  \in A\times B")
 = a")

 = b")

That’s going to be the key to the categorical product: it’s going to be defined primarily by the projection functions. We know that the only way we can talk about things in category theory is to use arrows. The thing that matters about a product is that it’s an object with projections to its two parts. We can describe that, in category theory, as something that we’ll call a wedge:

A wedge is basically an object, like the one in the diagram to the right, which we’ll call 



Now we get to the tricky part. The concept of a wedge captures the structure of what we mean by a product. But given two objects A and B, there isn’t just one wedge! In a category like Set, there are many different ways of creating objects with projections. Which object is the correct one to use for the product?
For example, I can have the set of triples ")
")

If, for two objects
Just a little while ago, we talked about initial and terminal objects. A terminal object can be understood as being a rough analog to a membership relation. We’re going to use that.
We can create a category of wedges 

In the category of wedges, what that means is that Y is at least as strict of a wedge than X; X has some amount of noise in it (noise in the sense of the C element of the triple from the example above), and Y cannot have any more noise than that. The true categorical product will be the wedge with no excess noise: an wedge which has an arrow from every other wedge in the category of wedges.
What’s an object with an edge from every other object? It’s the terminal object. The categorical product is the terminal wedge: the unique (up to isomorphism) object which is stricter than any other wedge.
Another way of saying that, using categorical terminology, is that there is a universal property of products: products have left and right projections. The categorical product is the exemplar of that property: it is the unique object which has exactly the property that we’re looking at, without any extraneous noise. Any property that this universal object has will be shared by every other product-like object.
This diagram should look familiar: it’s the same thing as the diagram for defining arrows in the category of wedges. It’s the universal diagram: you can substitute any wedge in for C, along with its project arrows (f, g).

We can pull that definition back to our original category, and define the product without the category of wedges. So given two objects, A and B, in a category, the categorical product is defined as an object which we’ll call 

:C \rightarrow (A\times B)")
On its own, if we’re looking specifically at sets, this is just a complicated way of defining the cartesian product of two values. It doesn’t really tell us much of anything new. What makes this interesting is that it isn’t limited to the cartesian product of two sets: it’s a general concept that takes what we understand about simple sets, and expands it to define a product of any two things in categories. The set-theoretic version only works for sets: this one works for numbers, posets, topologies, or anything else.
In terms of programming, products are pretty familiar to people who write functional programs: a product is a tuple. And the definition of a tuple in a functional language is pretty much exactly what we just described as the categorical product, tweaked to make it slightly easier to use.
For example, let’s look at the product type in Scala.
trait Product extends Any with Equals {
def productElement(n: Int): Any
def productArity: Int
...
}
The product object intrinsically wraps projections into a single function which takes a parameter and returns the result of applying the projection. It could have been implemented more categorically as:
trait CatProduct extends Any with Equals {
def projection(n: Int): () => Any
...
}
Implemented the latter way, to extract an element from a product, you’d have to write prod.projection(i)() which is more cumbersome, but does the same thing.
More, if you look at this, and think of how you’d use the product trait, you can see how it relates to the idea of terminal objects. There are many different concrete types that you could use to implement this trait. All of them define more information about the type. But every implementation that includes the concept of product can implement the Product trait. This is exactly the relationship we discussed when we used terminal objects to derive the ideal product: there are many abstractions that include the concept of the product; the categorical product is the one that abstracts over all of them.
The categorical product, as an abstraction, may not seem terribly profound. But as we’ll see in a the next post, in category theory, we can compose abstractions – and by using composition to in a compositional way, we’ll be able to define an abstraction of exponentiation, which generalizes the programming language concept of currying.
 by an abelian group
by an abelian group  consists of a group
consists of a group  together with an inclusion of
together with an inclusion of  as a normal subgroup and a surjective homomorphism
as a normal subgroup and a surjective homomorphism  that displays
that displays  .
.") , where:
, where: is a set of values;
is a set of values; is a total binary operator where:
is a total binary operator where:
 .
. * x = v * (w * x)")
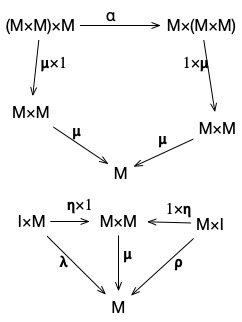
 is an arrow from
is an arrow from  , which we’ll call a multiplication operator.
, which we’ll call a multiplication operator. is an arrow from
is an arrow from  , called unit.
, called unit. is an arrow from
is an arrow from \times M \rightarrow M \times (M\times M)") which represents the associativity property of the monoid.
which represents the associativity property of the monoid. ), and
), and ") .
. \times M") composes with multiplication to be
composes with multiplication to be  .
.") .
.


 * z = x * (y * z)")

 .
. for which
for which  == g(x)") . We can take that set of values, and call it
. We can take that set of values, and call it  . (That is, the object and arrow that define C as a subobject of A.) This object and arrow must satisfy the following conditions:
. (That is, the object and arrow that define C as a subobject of A.) This object and arrow must satisfy the following conditions:
") if
if  then
then ") such that
such that 

 and
and  . Then the pullback of of f and g is the triple of an object and two arrows
. Then the pullback of of f and g is the triple of an object and two arrows ") . The elements of this triple must meet the following requirements:
. The elements of this triple must meet the following requirements:
 : B\times_A C \rightarrow A")
") , there is exactly one unique arrow
, there is exactly one unique arrow  where
where  , and
, and  .As happens so frequently in category theory, this is clearer using a diagram.
.As happens so frequently in category theory, this is clearer using a diagram.

 \in A \times B : f(x) = g(y) }")
 and
and  are equivalent if there is an isomorphism between X and Y.
are equivalent if there is an isomorphism between X and Y. such that
such that (That is, if any two arrows composed with
(That is, if any two arrows composed with  end up at the same object only if they are the same.)
end up at the same object only if they are the same.)") . If there are are two monic arrows
. If there are are two monic arrows  and
and  , and
, and , then we say
, then we say  (read “f factors through g”). Now, we can take that “≤” relation, and use it to define an equivalence class of morphisms using
(read “f factors through g”). Now, we can take that “≤” relation, and use it to define an equivalence class of morphisms using  .
. . We can construct a corresponding category
. We can construct a corresponding category ") . The objects in
. The objects in  corresponds to the set of expressions of type
corresponds to the set of expressions of type  that maps from
that maps from ![[A]](http://l.wordpress.com/latex.php?latex=%5BA%5D&bg=FFFFFF&fg=000000&s=0 "[A]") is the categorical interpretation of the type
is the categorical interpretation of the type ![\forall A \in \mbox{basetypes}(L), [A] = A_C \in C(L)](http://l.wordpress.com/latex.php?latex=%5Cforall%20A%20%5Cin%20%5Cmbox%7Bbasetypes%7D%28L%29%2C%20%5BA%5D%20%3D%20A_C%20%5Cin%20C%28L%29&bg=FFFFFF&fg=000000&s=0 "\forall A \in \mbox{basetypes}(L), [A] = A_C \in C(L)")
![[\mbox{unit}] = 1_C](http://l.wordpress.com/latex.php?latex=%5B%5Cmbox%7Bunit%7D%5D%20%3D%201_C&bg=FFFFFF&fg=000000&s=0 "[\mbox{unit}] = 1_C")
![[ A \times B] == [A] \times [B]](http://l.wordpress.com/latex.php?latex=%5B%20A%20%5Ctimes%20B%5D%20%3D%3D%20%5BA%5D%20%5Ctimes%20%5BB%5D&bg=FFFFFF&fg=000000&s=0 "[ A \times B] == [A] \times [B]")
![[A \rightarrow B] = [B]^{[A]}](http://l.wordpress.com/latex.php?latex=%5BA%20%5Crightarrow%20B%5D%20%3D%20%5BB%5D%5E%7B%5BA%5D%7D&bg=FFFFFF&fg=000000&s=0 "[A \rightarrow B] = [B]^{[A]}")
 , containing a set of type judgements. Each type judgement assigns a type to a lambda term. There are two translation rules for contexts:
, containing a set of type judgements. Each type judgement assigns a type to a lambda term. There are two translation rules for contexts:![[ \emptyset ] = 1_C](http://l.wordpress.com/latex.php?latex=%5B%20%5Cemptyset%20%5D%20%3D%201_C&bg=FFFFFF&fg=000000&s=0 "[ \emptyset ] = 1_C")
![[\Gamma, x: A] = [\Gamma] \times [A]](http://l.wordpress.com/latex.php?latex=%5B%5CGamma%2C%20x%3A%20A%5D%20%3D%20%5B%5CGamma%5D%20%5Ctimes%20%5BA%5D&bg=FFFFFF&fg=000000&s=0 "[\Gamma, x: A] = [\Gamma] \times [A]")
 , there is an arrow
, there is an arrow  .
.![[\Gamma :- x : A] = \mbox{arrow}](http://l.wordpress.com/latex.php?latex=%5B%5CGamma%20%3A-%20x%20%3A%20A%5D%20%3D%20%5Cmbox%7Barrow%7D&bg=FFFFFF&fg=000000&s=0 "[\Gamma :- x : A] = \mbox{arrow}") , where we’re saying that
, where we’re saying that  entails the type judgement
entails the type judgement  . What it means is the object corresponding to the type information covering a type inference for an expression corresponds to the arrow in
. What it means is the object corresponding to the type information covering a type inference for an expression corresponds to the arrow in ![[ \Gamma :- \mbox{unit}: \mbox{Unit}] = !: [\Gamma] \rightarrow [\mbox{Unit}]](http://l.wordpress.com/latex.php?latex=%20%5B%20%5CGamma%20%3A-%20%5Cmbox%7Bunit%7D%3A%20%5Cmbox%7BUnit%7D%5D%20%3D%20%21%3A%20%5B%5CGamma%5D%20%5Crightarrow%20%5B%5Cmbox%7BUnit%7D%5D&bg=FFFFFF&fg=000000&s=0 "[ \Gamma :- \mbox{unit}: \mbox{Unit}] = !: [\Gamma] \rightarrow [\mbox{Unit}]") . (A unit expression is a special arrow “!” to the unit object.)
. (A unit expression is a special arrow “!” to the unit object.)![[\Gamma :- a: A_C] = a \circ ! : [\Gamma] \rightarrow [A_C]](http://l.wordpress.com/latex.php?latex=%5B%5CGamma%20%3A-%20a%3A%20A_C%5D%20%3D%20a%20%5Ccirc%20%21%20%3A%20%5B%5CGamma%5D%20%5Crightarrow%20%5BA_C%5D&bg=FFFFFF&fg=000000&s=0 "[\Gamma :- a: A_C] = a \circ ! : [\Gamma] \rightarrow [A_C]") . (A simple value expression is an arrow composing with ! to form an arrow from Γ to the type object of Cs type.)
. (A simple value expression is an arrow composing with ! to form an arrow from Γ to the type object of Cs type.)![[\Gamma x: A :- x : A] = \pi_2 : ([\Gamma] \times [A]) \rightarrow [A]](http://l.wordpress.com/latex.php?latex=%20%5B%5CGamma%20x%3A%20A%20%3A-%20x%20%3A%20A%5D%20%3D%20%5Cpi_2%20%3A%20%28%5B%5CGamma%5D%20%5Ctimes%20%5BA%5D%29%20%5Crightarrow%20%5BA%5D&bg=FFFFFF&fg=000000&s=0 "[\Gamma x: A :- x : A] = \pi_2 : ([\Gamma] \times [A]) \rightarrow [A]") (A term which is a free variable of type A is an arrow from the product of Γ and the type object A to A; That is, an unknown value of type A is some arrow whose start point will be inferred by the continued interpretation of gamma, and which ends at A. So this is going to be an arrow from either unit or a parameter type to A – which is a statement that this expression evaluates to a value of type A.)
(A term which is a free variable of type A is an arrow from the product of Γ and the type object A to A; That is, an unknown value of type A is some arrow whose start point will be inferred by the continued interpretation of gamma, and which ends at A. So this is going to be an arrow from either unit or a parameter type to A – which is a statement that this expression evaluates to a value of type A.) , where
, where ![\pi_1: ([\Gamma] \times [A])\rightarrow [A](http://l.wordpress.com/latex.php?latex=%5Cpi_1%3A%20%28%5B%5CGamma%5D%20%5Ctimes%20%5BA%5D%29%5Crightarrow%20%5BA%27%5D&bg=FFFFFF&fg=000000&s=0 "\pi_1: ([\Gamma] \times [A])\rightarrow [A") (If the type rules of Γ plus the judgement
(If the type rules of Γ plus the judgement  , then the term
, then the term  . This is almost the same as the previous rule: it says that this will evaluate to an arrow for an expression that results in type
. This is almost the same as the previous rule: it says that this will evaluate to an arrow for an expression that results in type ![[\Gamma :- \lambda x:A . M : A \rightarrow B] = \mbox{curry}([\Gamma, x:A :- M:B]) : [\Gamma] \rightarrow B^{[A]}](http://l.wordpress.com/latex.php?latex=%5B%5CGamma%20%3A-%20%5Clambda%20x%3AA%20.%20M%20%3A%20A%20%5Crightarrow%20B%5D%20%3D%20%5Cmbox%7Bcurry%7D%28%5B%5CGamma%2C%20x%3AA%20%3A-%20M%3AB%5D%29%20%3A%20%5B%5CGamma%5D%20%5Crightarrow%20B%5E%7B%5BA%5D%7D&bg=FFFFFF&fg=000000&s=0 "[\Gamma :- \lambda x:A . M : A \rightarrow B] = \mbox{curry}([\Gamma, x:A :- M:B]) : [\Gamma] \rightarrow B^{[A]}") . (A function maps to an arrow from the type context to an exponential
. (A function maps to an arrow from the type context to an exponential ![[B]^{[A]}](http://l.wordpress.com/latex.php?latex=%5BB%5D%5E%7B%5BA%5D%7D&bg=FFFFFF&fg=000000&s=0 "[B]^{[A]}") , which is a function from
, which is a function from  ,
,  ,
,  . (function evaluation takes the eval arrow from the categorical exponent, and uses it to evaluate out the function.)
. (function evaluation takes the eval arrow from the categorical exponent, and uses it to evaluate out the function.)") , the objects and arrows of the categorical product
, the objects and arrows of the categorical product  .
. ,
, , called an evaluation map.
, called an evaluation map.") , an operation
, an operation  rightarrow (z rightarrow x^y)") . (That is, an operation mapping from arrows to arrows.)
. (That is, an operation mapping from arrows to arrows.) :
:
times 1_y)")
 = z")

 is the set of functions from Y to X.
is the set of functions from Y to X.") ,
, ") maps
maps ") , and currying it to
, and currying it to (y)") .
.") selects a function from
selects a function from , y)") .
.
: \exists_1 f: o \rightarrow b \in Mor(C)") . We generally write
. We generally write  for the initial object in a category. Similarly, there’s a dual concept of a terminal object
for the initial object in a category. Similarly, there’s a dual concept of a terminal object  , which is object for which there’s exactly one arrow from every object in the category to
, which is object for which there’s exactly one arrow from every object in the category to ") such that
such that  and
and  . If an object is initial, then there’s an arrow from it to every other object — including the other initial object. And there’s an arrow back, because the other one is initial. The iso-arrows between the two initials obviously compose to identities.
. If an object is initial, then there’s an arrow from it to every other object — including the other initial object. And there’s an arrow back, because the other one is initial. The iso-arrows between the two initials obviously compose to identities.") , the categorical product
, the categorical product  consists of:
consists of: , often written
, often written  ;
; and
and  , where
, where ") ,
,  , and
, and  .
. , maps the pair of arrows
, maps the pair of arrows  and
and to an arrow
to an arrow  , where
, where  has the
has the


