Introduction and Motivation
One thing that I keep bumping up against as an engineer who loves functional a programming is category theory. It often seems like there are two kinds of functional programmers: people who came into functional programming via engineering, and people who came into functional programming via math. The problem is that a lot of the really interesting work in languages and libraries for functional programming are being built from the mathematical side, but for people on the engineering side, it’s impenetrable: it’s like it’s written in a whole different language, and even basic discussions about programming go off the rails, because the basic abstractions don’t make any sense if you don’t know category theory.
But how do you learn category theory? It seems impenetrable to mere humans. For example, one of the textbooks on category theory that several people told me was the most approachable starts chapter one with the line:
A group extension of an abelian group  by an abelian group
by an abelian group  consists of a group
consists of a group  together with an inclusion of
together with an inclusion of  as a normal subgroup and a surjective homomorphism
as a normal subgroup and a surjective homomorphism  that displays as the quotient group
that displays as the quotient group  .
.
If you’re not a professional mathematician, then that is pure gobbledigook. But that seems to be typical of how initiates of category theory talk about it. But the basic concepts, while abstract, really aren’t all that tricky. In many ways, it feels a lot like set theory: there’s a simple conceptual framework, on which you can build extremely complicated formalisms. The difference is that while many people have spent years figuring out how to make the basics of set theory accessible to lay-people, but that effort hasn’t been applied to set theory.
What’s the point?
Ok, so why should you care about category theory?
Category theory is a different way of thinking, and it’s a language for talking about abstractions. The heart of engineering is abstraction. We take problems, and turn them into abstract structures. We look at the structures we create, and recognize commonalities between those structures, and then we create new abstractions based on the commonalities. The hardest part of designing a good library is identifying the right abstractions.
Category theory is a tool for talking about structures, which is particularly well suited to thinking about software. In category theory, we think in terms of arrows, where arrows are mappings between objects. We’ll see what that means in detail later, but the gist of it is that one example of arrows mapping between objects is functions mapping between data types in a computer program.
Category theory is built on thinking with orrows, and building structures using arrows. It’s about looking at mathematical constructions built with arrows, and in those structures, figuring out what the fundamental parts are. When we abstract enough, we can start to see that things that look very different are really just different realizations of the same underlying structure. Category theory gives us a language and a set of tools for doing that kind of abstraction – and then we can take the abstract structures that we identify, and turn them into code – into very generic libraries that express deep, fundamental structure.
Start with an Example: Monoids
Monoids in Code
We’ll get started by looking at a simple mathematical structure called a monoid, and how we can implement it in code; and then, we’ll move on to take an informal look at how it works in terms of categories.
Most of the categorical abstractions in Scala are implemented using something called a typeclass, so we’ll start by looking at typeclasses. Typeclasses aren’t a category theoretical notion, but they make it much, much easier to build categorical structures. And they do give us a bit of categorical flavor: a typeclass defines a kind of metatype – that is, a type of type – and we’ll see, that kind of self-reflective abstraction is a key part of category theory.
The easiest way to think about typeclasses is that they’re a kind of metatype – literally, as the name suggests, they define classes where the elements of those classes are types. So a typeclass provides an interface that a type must provide in order to be an instance of the metatype. Just like you can implement an interface in a type by providing implementations of its methods, you can implement a typeclass by providing implementations of its operations.
In Scala, you implement the operations of a typeclasses using a language construct called an implicit parameter. The implicit parameter attaches the typeclass operations to a meta-object that can be passed around the program invisibly, providing the typeclass’s operations.
Let’s take a look at an example. An operation that comes up very frequently in any kind of data processing code is reduction: taking a collection of values of some type, and combining them into a single value. Taking the sum of a list of integers, the product of an array of floats, and the concatenation of a list of strings are all examples of reduction. Under the covers, these are all similar: they’re taking an ordered group of values, and performing an operation on them. Let’s look at a couple of examples of this:
def reduceFloats(floats: List[Float]): Float =
floats.foldRight(0)((x, y) => x + y)
def reduceStrings(strings: Seq[String]): String =
strings.foldRight("")((x, y) => x.concat(y))
When you look at the code, they look very similar. They’re both just instantiations of the same structural pattern:
def reduceX(xes: List[X]): X =
xes.foldRight(xIdentity)((a, b) => Xcombiner(a, b))
The types are different; the actual operation used to combine the values is different; the base value in the code is different. But they’re both built on the same pattern:
- There’s a type of values we want to combine:
Float or String. Everything we care about in reduction is a connected with this type.
- There’s a collection of values that we want to combine, from left to right. In one case, that’s a
List[Float], and in the other, it’s a Seq[String]. The type doesn’t matter, as long as we can iterate over it.
- There’s an identity value that we can use as a starting point for building the result;
0 for the floats, and "" (the empty string) for the strings.
- There’s an operation to combine two values:
+ for the floats, and concat for the strings.
We can capture that concept by writing an interface (a trait, in Scala terms) that captures it; that interface is called a typeclass. It happens that this concept of reducible values is called a monoid in abstract algebra, so that’s the name we’ll use.
trait Monoid[A] {
def empty: A
def combine(x: A, y: A): A
}
We can read that as saying “A is a monoid if there are implementations of empty and combine that meet these constraints”. Given the declaration of the typeclass, we can implement it as an object which provides those operations for a particular type:
object FloatAdditionMonoid extends Monoid[Float] {
def empty: Float = 0.0
def combine(x: Float, y: Float): Float = x + y
}
object StringConcatMonoid extends Monoid[String] {
def empty: String = ""
def combine(x: String, y: String): String = x.concat(y)
}
FloatAdditionMonoid implements the typeclass Monoid for the type Float. And since we can write an implementation of Monoid for Float or String, we can say that the types Float and String are instances of the typeclass Monoid.
Using our implementation of Monoid, we can write a single, generic reduction operator now:
def reduce[A](values: Seq[A], monoid: Monoid[A]): A =
values.foldRight(monoid.empty)(monoid.combine)
We can use that to reduce a list of floats:
reduce([1.0, 3.14, 2.718, 1.414, 1.732], FloatAdditionMonoid)
And we can do a bit better than that! We can set up an implicit, so that we don’t need to pass the monoid implementation around. In Scala, an implicit is a kind of dynamically scoped value. For a given type, there can be one implicit value of that type in effect at any point in the code. If a function takes an implicit parameter of that type, then the nearest definition in the execution stack will automatically be inserted if the parameter isn’t passed explicitly.
def reduce[A](values: Seq[A])(implicit A: Monoid[A]): A =
list.foldRight(A.empty)(A.combine)
And as long as there’s a definition of the Monoid for a type A in scope, we can can use that now by just writing:
implicit object FloatAdditionMonoid extends Monoid[Float] {
def empty: Float = 0.0
def combine(x: Float, y: Float): Float = x + y
}
val floats: List[Float] = ...
val result = reduce(floats)
Now, anywhere that the FloatAdditionMonoid declaration is imported, you can call reduce on any sequence of floats, and the implicit value will automatically be inserted.
Using this idea of a monoid, we’ve captured the concept of reduction in a common abstraction. Our notion of reduction doesn’t care about whether we’re reducing strings by concatenation, integers by addition, floats by multiplication, sets by union. Those are all valid uses of the concept of a monoid, and they’re all easy to implement using the monoid typeclass. The concept of monoid isn’t a difficult one, but at the same time, it’s not necessarily something that most of us would have thought about as an abstraction.
We’ve got a typeclass for a monoid; now, we’ll try to connect it into category theory. It’s a bit tricky, so we won’t cover it all at once. We’ll look at it a little bit now, and we’ll come back to it in a later lesson, after we’ve absorbed a bit more.
From Sets to Arrows
For most of us, if we’ve heard of monoids, we’ve heard of them in terms of set theory and abstract algebra. So in that domain, what’s a monoid?
A monoid is a triple ") , where:
, where:
 is a set of values;
is a set of values; is a value in ;
is a value in ; is a total binary operator where:
is a total binary operator where:
- is an identity of : For any value
 .
.
- is associative: for any values
 * x = v * (w * x)")
That’s all just a formal way of saying that a monoid is a set with a binary associative operator and an identity value. The set of integers can form a monoid with addition as the operator, and 0 as identity. Real numbers can be a monoid with multiplication and 1. Strings can be a monoid with concatenation as the operator, and empty string as identity.
But we can look at it in a different way, too, by thinking entirely in terms of function.
Let’s forget about the numbers as individual values, and instead, let’s think about them in functional terms. Every number is a function which adds itself to its parameter. So “2” isn’t a number, it’s a function which adds two to anything.
How can we tell that 2 is a function which adds two to things?
If we compose it with 3 (the function that adds three to things), we get 5 (the function that adds five to things). And how do we know that? Because it’s the same thing that we get if we compose 3 with 1, and then compose the result of that with 1 again. 3+1+1=5, and 3+2=5. We can also tell that it’s 2, because if we just take 1, and compose it with itself, what we’ll get back is the object that we call 2.
In this scheme, all of the numbers are related not by arithmetic, not by an underlying concept of quantity or cardinality or ordinality, but only by how they compose with each other. We can’t see anything else – all we have are these functions. But we can recognize that they are the natural numbers that we’re familiar with.
Looking at it this way, we can think of the world of natural numbers as a single point, which represents the set of all natural numbers. And around that point, we’ve got lots and lots of arrows, each of which goes from that point back to itself. Each of those arrows represents one number. The way we tell them apart is by understanding which arrow we get back when we compose them. Take any arrow from that point back to that point, and compose it with the arrow 0, and what do you get? The arrow you started with. Take any arrow that you want, and compose it with 2. What do you get? You get the same thing that you’d get if you composed it with 1, and then composed it with one again.
That dot, with those arrows, is a category.
What kind of advantage do we get in going from the algebraic notion of a set with a binary operation, to the categorical notion of an object with a bunch of composable arrows? It allows to understand a monoid purely as a structure, without having the think about what the objects are, or what the operator means.
Now, let’s jump back to our monoid typeclass for a moment.
trait Monoid[A] {
def empty: A
def combine(x: A, y: A): A
}
We can understand this as being a programmable interface for the categorical object that we just described. All we need to do is read “:” as “is an arrow in”: It says that A is a monoid if:
- It has an element called empty which is an arrow in A.
- It has an operation called combine which, given any two arrows in A, composes them into a new arrow in A.
There are, of course, other conditions – combine needs to be associative, and empty needs to behave as the identity value. But just like when we write an interface for, say, a binary search tree, the interface only defines the structure not the ordering condition, the typeclass defines the functional structure of the categorical object, not the logical conditions.
This is what categories are really all about: tearing things down to a simple core, where everything is expressed in terms of arrows. It’s almost reasoning in functions, except that it’s even more abstract than that: the arrows don’t need to be functions – they just need to be composable mappings from things to things.
Deeper Into Arrows
We can abstract a bit more, and look at the entire construction, including the identity and associativity constraints entirely in terms of arrows. To really understand this, we’ll need to spend some time diving deeper into the actual theory of categories, but as a preview, we can describe a monoid with the following pair of diagrams (copied from wikipedia):

In these diagrams, any two paths between the same start and end-nodes are equivalent (up to isomorphism). When you understand how to read this diagrams, these really do define everything that we care about for monoids.
For now, we’ll just run through and name the parts – and then later, in another lesson, we’ll come back, and we’ll look at this in more detail.
 is an arrow from
is an arrow from  , which we’ll call a multiplication operator.
, which we’ll call a multiplication operator. is an arrow from
is an arrow from  , called unit.
, called unit. is an arrow from
is an arrow from \times M \rightarrow M \times (M\times M)") which represents the associativity property of the monoid.
which represents the associativity property of the monoid. is a morphism which represents the left identity property of the monoid (that is,
is a morphism which represents the left identity property of the monoid (that is,  ), and
), and  is a morphism representing the right identity property
is a morphism representing the right identity property ") .
.
This diagram, using these arrows, is a way of representing all of the key properties of a monoid via nothing but arrows and composition. It says, among other things, that:
 \times M") composes with multiplication to be
composes with multiplication to be  .
.
That is, applying multiplication to evaluates to (M \times M).- composed with associativity can become
") .
.
So it’s a monoid – but it’s a higher level monoid. In this,  isn’t just an object in a category: it’s an entire category. These arrows are arrows between categories in a category of categories.
isn’t just an object in a category: it’s an entire category. These arrows are arrows between categories in a category of categories.
What we’ll see when we get deeper into category theory is how powerful this kind of abstraction can get. We’ll often see a sequence of abstractions, where we start with a simple concept (like monoid), and find a way to express it in terms of arrows between objects in a category. But then, we’ll lift it up, and look at how we can see in not just as a relation between objects in a category, but as a different kind of relation between categories, by constructing the same thing using a category of categories. And then we’ll abstract even further, and construct the same thing using mappings between categories of categories.
(You can find the next lesson <a href=”http://www.goodmath.org/blog/2019/02/20/category-theory-lesson-2-basics-of-categorical-abstraction/”>here</a>.)
Like this:
Like Loading...










 ; or in english, “not A” is the same thing as “not(A nand A)”. In gates, that’s easy to build: it’s a NAND gate with both of its inputs coming from the same place:
; or in english, “not A” is the same thing as “not(A nand A)”. In gates, that’s easy to build: it’s a NAND gate with both of its inputs coming from the same place: . It’s pretty straightforward in terms of logic: “
. It’s pretty straightforward in terms of logic: “ ” is the same as
” is the same as ") .
.









 ) is less than one, then the point is inside the circle. If it isn’t, then it’s outside of the circle.
) is less than one, then the point is inside the circle. If it isn’t, then it’s outside of the circle. , of any given random point being inside that circle is equal to the ratio of the area of the circle to the area of the square. The area of that region of the circle is:
, of any given random point being inside that circle is equal to the ratio of the area of the circle to the area of the square. The area of that region of the circle is:  , and the area of the the square is
, and the area of the the square is  . So the probability is
. So the probability is \pi/1") , or
, or  .
.
 .
. to
to  as:
as:  – that is, as exponentiation of the range of the produced functions.
– that is, as exponentiation of the range of the produced functions. .
. , which we’ll call eval.
, which we’ll call eval. and an element of
and an element of  which have the necessary product with
which have the necessary product with  is an object where the following product and arrow exist:
is an object where the following product and arrow exist: to an object
to an object  if the following conditions hold in the base category:
if the following conditions hold in the base category:: X \rightarrow Y") in the base category.
in the base category.\times id_A: X\times A \rightarrow Y\times A")
\times id_A=\text{eval}_y y")
 .
. .
. which converts a value of
which converts a value of \times\text{id}_A: X\times A \rightarrow Y\times A") , which given a pair
, which given a pair  \in X\times A") transforms it into a pair
transforms it into a pair  \in Y\times A") , where evaluating
, where evaluating =\text{eval}_y(\text{curry}(x, a))") . In other words, if we restrict the inputs to
. In other words, if we restrict the inputs to  might have a larger domain than the range of
might have a larger domain than the range of  , and one from
, and one from  . Since the two arrows are deeply related (they’re one arrow in the category of potential exponentials), we’ll call them
. Since the two arrows are deeply related (they’re one arrow in the category of potential exponentials), we’ll call them ") and
and \times id_A") . (Note that we’re not really taking the product of an arrow here: we haven’t talked about anything like taking products of arrows! All we’re doing is giving the arrow a name that helps us understand it. The name makes it clear that we’re not touching the right-hand component of the product.)
. (Note that we’re not really taking the product of an arrow here: we haven’t talked about anything like taking products of arrows! All we’re doing is giving the arrow a name that helps us understand it. The name makes it clear that we’re not touching the right-hand component of the product.) . Since
. Since  represents the application of one of those functions to a value of type
represents the application of one of those functions to a value of type 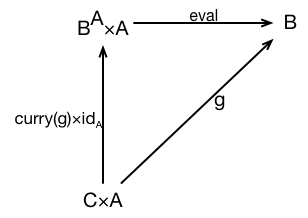
 , there is a unique function (arrow)
, there is a unique function (arrow)  to exist,
to exist,  , then we’ll say that
, then we’ll say that ") , there exists a product object
, there exists a product object  , we say that the category has products.
, we say that the category has products.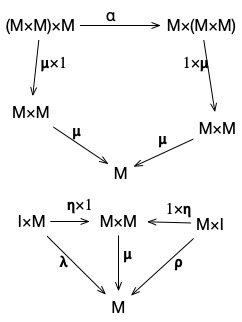
") is defined via primitive recursion if, for some other formulae
is defined via primitive recursion if, for some other formulae  and
and  = \psi(x_2, ..., x_n)")
 = \mu(i, \phi(i, x_2, ..., x_n), x_2, ..., x_n)") .
. can invoked recursively. When it’s 0, you can’t invoke
can invoked recursively. When it’s 0, you can’t invoke  any more.
any more. where any formula
where any formula  is defined via primitive recursion from
is defined via primitive recursion from  , or the primitive succ function from Peano arithmetic.
, or the primitive succ function from Peano arithmetic. in that sequence, the degree of the formula is the number of other primitive recursive formulae used in its definition.
in that sequence, the degree of the formula is the number of other primitive recursive formulae used in its definition.") is primitive recursive if and only if there exists a primitive recursive function
is primitive recursive if and only if there exists a primitive recursive function  = 0") .
.") and
and ") are primitive recursive functions, then the relation
are primitive recursive functions, then the relation  \Leftrightarrow (\phi(x_1, ..., x_n) = \psi(x_1, ..., x_n)") is also primitive recursive.
is also primitive recursive. and
and  be finite-length tuples of variables. If the function
be finite-length tuples of variables. If the function ") and the relation
and the relation ") are primitive recursive, then so are the relations:
are primitive recursive, then so are the relations:
 \Leftrightarrow (\exists y \le \phi(xv). R(y, zv))")
 \Leftrightarrow (\forall y \le A(xv). R(y, zv))")
![text{argmin}[y le f(x).R(x)]](http://l.wordpress.com/latex.php?latex=text%7Bargmin%7D%5By%20le%20f%28x%29.R%28x%29%5D&bg=FFFFFF&fg=000000&s=0 "text{argmin}[y le f(x).R(x)]") be the smallest value of
be the smallest value of  for which
for which ") and
and ") is true, or 0 if there is no such value. Then if the function
is true, or 0 if there is no such value. Then if the function ") and the relation
and the relation ![P(xv, zv) = (\text{argmin}[y \le A(xv). R(y, zv))]](http://l.wordpress.com/latex.php?latex=P%28xv%2C%20zv%29%20%3D%20%28%5Ctext%7Bargmin%7D%5By%20%5Cle%20A%28xv%29.%20R%28y%2C%20zv%29%29%5D&bg=FFFFFF&fg=000000&s=0 "P(xv, zv) = (\text{argmin}[y \le A(xv). R(y, zv))]") .
.